

Spike-triggered covariance (STC) is a method of estimating receptive fields with quadratic or more generally symmetric nonlinearities in stimulus space. The basis idea behind spike-triggered covariance is that the ensemble of stimuli which drive a cell has different statistical properties than the ensemble of all stimuli that are presented to a neuron. In particular if the baseline stimulus ensemble has a symmetric Gaussian distribution, then the empirical covariance of the spike-triggered ensemble (STE) can be estimated, and the eigenvectors of the covariance matrix corresponding to large or small eigenvalues correspond to directions in stimulus space with excitatory or inhibitory symmetric nonlinearities.
Here is Figure 4B of Schwartz et al. 2006 which illustrates the idea. The stimulus ensemble is illustrated in black, while the STE is illustrated in white. The variance of the STE is noticeably smaller in the -30 degree direction, and an eigenvalue decomposition of the covariance of the STE would thus find a small eigenvalue corresponding to the [cos(-pi/6),sin(-pi/6)] eigenvector. Thus there is an inhibitory symmetric nonlinearity in the [cos(-pi/6),sin(-pi/6)] direction. STC is most useful in systems with quadratic nonlinearities, for example to determine the properties of complex cells in V1.

This is all fine and dandy, but spike-triggered covariance works by estimating the generative distribution of the STE, while other RF estimation methods (linear regression, GLMs, etc.) are discriminative, and thus do not search to estimate the generative distribution of the STE but rather directly discriminate the STE distribution and the baseline stimulus distribution. Is it possible to get the benefits of STC (quadratic nonlinearities, dimensionality reduction through the eigenvalue decomposition) while working in a regression or discriminative framework?
You bet. Marmarelis (2003) discusses this in the context of temporal nonlinearities (he calls this method principal dynamic modes), but it also works in the spatial case. Consider a general quadratic system:

Here x is the stimulus, y the response, and 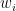

What is interesting is that if we can estimate the quadratic form Q then we can perform an eigenvalue decomposition of Q like so:

Thus if we can estimate Q we can perform an eigenvalue decomposition to obtain a quadratic system of the form of equation (1) with filters 
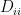
Simply write down the action of Q explicitly:
![x'Qx = \\ q_{11} x_1^2 + q_{22} x_2^2 + \ldots + 2 q_{12} x_1 x_2 + 2 q_{13} x_1 x_3 + \ldots = \\ \mbox{} [x_1^2,x_2^2,\ldots,2x_1x_2,2x_1x_3\ldots]\cdot[q_{11},q_{22},\ldots,q_{12},q_{13},\ldots]'](https://s0.wp.com/latex.php?latex=x%27Qx+%3D+%5C%5C+q_%7B11%7D+x_1%5E2+%2B+q_%7B22%7D+x_2%5E2+%2B+%5Cldots+%2B+2+q_%7B12%7D+x_1+x_2+%2B+2+q_%7B13%7D+x_1+x_3+%2B+%5Cldots+%3D+%5C%5C+%5Cmbox%7B%7D+%5Bx_1%5E2%2Cx_2%5E2%2C%5Cldots%2C2x_1x_2%2C2x_1x_3%5Cldots%5D%5Ccdot%5Bq_%7B11%7D%2Cq_%7B22%7D%2C%5Cldots%2Cq_%7B12%7D%2Cq_%7B13%7D%2C%5Cldots%5D%27&bg=ffffff&fg=000&s=0&c=20201002)
The right hand side takes the form of the multiplication of a fixed vector that will be turned into a matrix once we have multiple observations with a vector of unknowns. Thus this vector of unknowns can be estimated through standard methods (linear regression, GLMs or otherwise).
Did you follow any of this? If not, perhaps some example code will be helpful. Here I simulate the output of the sum of the squares of a one-dimensional quadrature pair of Gabors and I recover the filters through the above method (the result is what’s shown at the start of the post):
function stcExample()
%Simulate the output of quad pair of Gabors
rg = (-7:8)';
sigma = 1.6;
gab1 = exp(-rg.^2/1/sigma^2).*cos(rg*2*pi/4);
gab2 = exp(-rg.^2/1/sigma^2).*sin(rg*2*pi/4);
gab1 = gab1 - mean(gab1)*exp(-rg.^2/1/sigma^2)/mean(exp(-rg.^2/1/sigma^2));
%Probe filters with random stimuli
X = randn(2000,16);
%response w/Poisson noise
r = poissrnd(.5*((X*gab1).^2+(X*gab2).^2));
%Recover the filter
%Create the matrix of products
X2 = anovize(X);
%Estimate the params through linear regression
ws = [X2,ones(size(X2,1),1)]\r;
%Form the Q matrix
Q = deanovize(ws,size(X,2));
%Take the first 6 eigenvalues
[V,D] = eigs(Q,6);
%Plot the results
subplot(2,3,1);plot(gab1);title('Orig filter 1');
subplot(2,3,2);plot(gab2);title('Orig filter 2');
subplot(2,3,4);plot(V(:,1));title('Est filter 1');
subplot(2,3,5);plot(V(:,2));title('Est filter 2');
subplot(2,3,3);plot(diag(D),'.');title('Eigenvalues');
subplot(2,3,6);imagesc(Q);title('Q matrix');
end
function [Y] = anovize(X)
Y = zeros(size(X,1),(size(X,2)+1)*(size(X,2)/2));
Y(:,1:size(X,2)) = X.^2;
offset = size(X,2);
for ii = 2:size(X,2)
Y(:,offset + (1:size(X,2)+1-ii)) = 2*X(:,1:end-ii+1).*X(:,ii:end);
offset = offset + size(X,2) + 1 - ii;
end
end
function [Y] = deanovize(w,n)
Y = zeros(n,n);
offset = 0;
for ii = 1:n
rg = offset + (1:n+1-ii);
Y(sub2ind([n,n],(1:n+1-ii)',(ii:n)')) = w(rg);
offset = rg(end);
end
Y = Y + triu(Y)';
end

One response to “An alternative method for spike-triggered covariance”
[…] if you plot the singular values, you should see that they drop off rapidly after the first few (as with an eigenvalue decomposition), and this can be used as a means of finding a good point to truncate the decomposition. More […]