
")
Introduction
Olshausen and Field (1996) made a big splash in visual neurophysiology and machine learning by offering an answer to a provocative question:
Why are simple cell receptive fields (RFs) organized the way they are?
After all, they could just as well be shaped like elongated sine waves, as in Fourier analysis, or they could be like bigger LGN receptive fields. Yet, evolution has selected local, oriented, band-pass receptive fields that resemble Gabor functions. Why?
Leibniz offered that we live in the best of all possible worlds, and while this idea was ridiculed by many, the co-inventor of calculus may have been on to something. Sensory systems are under a wide array of conflicting constraints: they should minimize energy consumption and wiring length without sacrificing acuity, for example. Perhaps the visual system is the way it is because it satisfies an optimality principle.
One desirable property for a neural code is sparseness. A vector is sparse if most of its elements are close to zero, and a few of its elements are large in magnitude. In a neural context, that means that a minority of neurons are needed to encode a typical stimulus.
Sparse codes can be advantageous compared to alternative neural codes. They can be energy efficient compared to distributed codes, since only a few cells are active per stimuli. They require fewer neurons than grandmother cell codes. Finally, retinotopic sparse codes can keep wiring to a minimum.
How does one build a sparse code? As I mentioned earlier, a sparse code should have the property that the firing rate distribution is sparse for typical stimuli. Thus, one could build a sparse code by training model V1 neurons to encode natural image patches with accuracy and sparseness. Olshausen and Field postulate that the code should be such that the original stimulus can be reconstructed easily from the distribution of firing rates through a linear readout rule.
This is a subtle idea. When we think of a V1 simple cell, we usually think of its receptive field as a filter that acts on the retinal image. A radically different way of looking at a V1 cell is that it has a synthetic field. The firing rates of simple cells combined with the knowledge of the cells’ synthetic fields reconstruct the retinal image. Thus, a cell’s receptive field is the shadow of its synthetic field, so to speak. The ensemble of synthetic fields form a generative model for images, while the receptive fields are epiphenomena of the construction of the generative model. I should note that synthetic field is not a standard term, but I will use it here to avoid confusion.
To understand the receptive/synthetic distinction in detail, we need to look at how we can learn a sparse code for images in practice.
The math and the code
Here I follow Lee et al. (2007), who present the mathematical and algorithmic aspects of sparse coding lucidly. Note that this is not the exact flavor of sparse coding in O&F, but it’s similar enough.
Suppose that we have a database of images, which we write as a matrix 
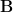
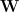
We would like to be able to reconstruct the stimuli given the activations to a good accuracy, and thus minimize the sum-of-squares reconstruction error 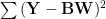

Here 
Thus, to determine both the synthetic fields and the population firing rates, we alternate between learning synthetic fields and learning firing rates. Here’s some nice Matlab code that implements this algorithm.
The subtlety of sparse coding
Once we’ve learned the synthetic fields, we can visualize them. Up top is such an example of a basis for sparse coding obtained by training the model on a database of natural image patches, reprinted from Lee et al. (2007). The synthetic fields are band-pass and oriented, and, as I will show later, the receptive fields are as well.
These are not the receptive fields of the model neurons, however. Furthermore, although the generative model for the images is linear, the processing of the model neurons (the receptive field) is not linear.
In the previous section, I showed that to get the population firing rates we have to solve a LASSO problem . You can’t do that by linear processing. The receptive fields are nonlinear by virtue of the sparsification, and can display effects which mimic non-classical effects.
Suppose that in the population of synthetic fields, there are some which are elongated and some which are less so (stubs). If you have a short line, for example, it might be generated most sparsely by stubs. As the line is lengthened, however, an elongated synthetic field will capture the image better.
")
So while the synthetic field of the stub is linear, its firing rate will decrease when the line is lengthened. This is despite the fact that the extra length lies outside the synthetic field. Lee et al. show that sparse coding yields end-stopped model neurons (reprinted above). Interestingly, Vinje and Gallant (2000) show that firing rate distributions become sparser as stimuli become bigger, when extra-classical effects kick in.
Hence, not only does sparse coding it replicate the orientation and spatial frequency selectivity of simple cells, it also explains some non-classical effects. In addition to end-stopping, cells can show cross-orientation suppression and facilitation effects. Once we implement it in a neural network, sparse coding can also show interesting temporal effects, as I show next.
Temporal dynamics
I showed previously that for fixed synthetic fields, the activations of the model neurons can be inferred through solving a LASSO problem. There’s at least a dozen different ways of solving the LASSO problem numerically, most of which would map poorly to a neural network. Olshausen and Field (1997) shows one implementation of sparse coding as a neural network. Here is a similar but different, and, as far as I know, previously unpublished implementation that I think is fairly intuitive.
One LASSO solver that has a straightforward neural network implementation is called iterative thresholding, also known as fixed-point continuation (Hale, Yin and Zhang, 2008). It works like this. We want to solve:

To obtain the population firing rate 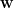
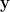
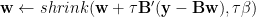
Where shrink is the soft-threshold operator:
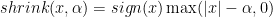
And

- take the current activations of the neurons (
- add to this an amount proportional to the match of the feedforward input with the synthetic field of the model neuron (
)
- remove from this an amount that depends on the current activation (
)
B’B computes the overlap of the perceptive fields. Thus, 
Thus the model neurons start out with an activation which is proportional to their feedforward input, and their tuning is sharpened in time through recurrent inhibitory connections. As time passes on, not only does orientation and spatial frequency tuning sharpen, but extra-classical effects like end-stopping also kick in, which is consistent with Pack et al. (2003).
Conclusion
Olshausen and Field started out with a very simple, intuitive premise: images should be encoded efficiently in cortex. Using sparseness as a proxy for efficiency, one can derive a number of known properties of simple cells: they are band-pass, oriented, some are end-stopped, some have cross-orientation inhibition, they have non-trivial temporal dynamics, their tuning sharpens with time, and so forth.
Others have considered alternative optimality principles with great success. Although ICA predates sparse coding, following O&F, ICA has been used to derive properties of sensory systems. Slow-feature analysis is another scheme that has been inspired by this work. Others have looked at extending the generative model in a hierarchical framework, with intriguing results.
Thus, optimal coding and the sparse coding principle have had far-reaching and continuing influence on our understanding of sensory systems.
References
![]()
Olshausen, B., & Field, D. (1996). Emergence of simple-cell receptive field properties by learning a sparse code for natural images Nature, 381 (6583), 607-609 DOI: 10.1038/381607a0
Honglak Lee, Alexis Battle, Rajat Raina, & Andrew Y. Ng (2007). Efficient Sparse Coding Algorithms. Advances in Neural Information Processing Systems, 19, 801-808. Available online
Vinje WE, & Gallant JL (2000). Sparse coding and decorrelation in primary visual cortex during natural vision. Science (New York, N.Y.), 287 (5456), 1273-6 PMID: 10678835
Olshausen BA, & Field DJ (1997). Sparse coding with an overcomplete basis set: a strategy employed by V1? Vision research, 37 (23), 3311-25 PMID: 9425546
Hale, E., Yin, W., & Zhang, Y. (2008). Fixed-Point Continuation for L1-Minimization: Methodology and Convergence SIAM Journal on Optimization, 19 (3) DOI: 10.1137/070698920
Pack CC, Livingstone MS, Duffy KR, & Born RT (2003). End-stopping and the aperture problem: two-dimensional motion signals in macaque V1. Neuron, 39 (4), 671-80 PMID: 12925280

5 responses to “The far-reaching influence of sparse coding in V1”
[…] https://xcorr.net/2011/06/15/the-far-reaching-influence-of-sparse-coding-in-v1/ […]
[…] one buzz word would be ‘sparse coding’. Only a minority of units are needed to encode a typical stimulus. This is well documented in the […]
Hi Patrick,
first of all thank you for the blog and really interesting posts.
I think that in the matrix Y, M should be the number of pixel and N the number of images. In fact the column of B, that represents the basis, has to have the same dimension of the image they produce.
Hi Patrick,
first of all thank you for the blog and really interesting posts.
I think that in the matrix Y, M should be the number of pixel and N the number of images. In fact the column of B, that represents the basis, has to have the same dimension of the image they produce.
[…] primates aren’t sensitive to infrared, for instance. This sort of argument can be solved by stacking a series of optimality principles: maximal information capacity, minimal wiring length, minimal energy use, […]