
Cortical spike trains roughly follow Poisson statistics. When it comes to modeling the spike rate as a function of a stimulus, in a receptive field estimation context, for example, it’s thus natural to use the Poisson GLM. In the Poisson GLM with canonical link, the rate is assumed to be generated by a weighted sum of the inputs 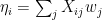

There’s other choices as well which will leave the likelihood log-concave, and thus fittable without headaches (see section 4 here). One reason you might want to use these other choices instead of the exponential is that the exponential blows up to infinity. So if your model parameters are poorly constrained, you might have a very large predicted rate for some stimuli. In fact the predicted rate might be so large as to be unphysical. This is exacerbated if you do prediction using ML/MAP estimated on a completely different set of stimuli than those you used to fit. Unfortunately, while there are other choices for links which increase slower than exponential while leaving the likelihood log-concave, none of these static nonlinearities are bounded. That’s a bummer, because we know that physically the spike rate can’t be more than umpteen spikes per second.
So what can you do? It’s often said that by adding in a negative delay current after a spike, that naturally bounds the spike rate to a sensible range. That solution only works if you use small bins, at most 2ms. But what if you can’t afford to use small bins for computational reasons?
Use the binomial GLM instead! The binomial GLM naturally comes with a logistic canonical inverse link, which bounds the output from 0..1. To handle bins which contain more than one spike per bin, you pretend that the number of spikes in a bin is the number of successes out of N binomial trials. You select N on physical grounds. For example, if you use 20 ms bins (50Hz), then setting N = 8 means that the maximal sustained firing rate for your modeled cell is 400Hz. Now your predictions are guaranteed to be bounded.
The binomial GLM relates to the Poisson in a natural way. With 20 ms bins and N = 8, you’re saying in essence that there cannot be more than 1 spike per 2.5ms bin, and that the probability of a spike within a bin is equal to 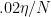

One response to “Using the binomial GLM instead of the Poisson for spike data”
[…] Using the binomial GLM instead of the Poisson for spike data (xcorr.net) […]