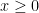Sparseness priors, which impose that most of the weights are small or zero, are very effective in constraining regression problems. The prototypical sparseness prior is the Laplacian prior (aka L1-prior), which imposes a penalty on the absolute value of individual weights. Regression problems (and GLMs) with Laplacian priors can be easily solved by Maximum a Posteriori methods; the negative log-posterior is convex in the model parameters.
It’s also possible to assume that model weights are non-negative, in addition to being sparse. Such non-negative sparse priors are less frequently used that straight sparseness priors, but they can be useful from time to time. You might have a model where model parameters cannot logically be negative, on physical grounds. Or you might want to express a database of images as a sum of features.
Perhaps surprisingly, it’s pretty easy to solve for such problems. Patrik Hoyer shows in his non-negative sparse coding paper how to solve for model weights using a simple iterative method here. He has software available which implements non-negative sparse coding, non-negative matrix factorization, and associated algorithms.
YALL1 (Your ALgorithms for L1) is a Matlab package which can solve many problems related to L1. This includes what it calls the L1/L2+ problem,