
Today was a little less intense than yesterday, mercifully.
Geoff Boynton
Geoff did a tutorial on signal detection theory and estimating psychophysical measures in Matlab. He emphasized that given the signal detection model, it is easy to find good estimates using Bayesian inference. Whenever the observer’s response is binary, you should use the binomial likelihood as opposed to least-squares (people still do that? unbelievable).
The framework of signal detection theory can be used to analyze a wide variety of experiments. He showed how, in a divided attention task, the accuracy of the observer can be increased when the location of the stimulus is cued despite no real decrease in the noise (equivalently, without an increase in the gain of the neural response).
The design of psychophysical experiments was briefly discussed, with an emphasis on the usefulness of 2AFC designs over yes/no. Geoff prefers the 3 down and 1 up staircase for estimating thresholds; it guarantees an observer performance of (1/2)^(1/3) in the long run, corresponding to 79% accuracy. He analyzed the 3 down/1 up procedure for a previous CSHL meeting and found that it’s practically as efficient as QUEST or PEST once you take into account lapses.
There was an interesting discussion of using a ratings scale rather than a yes/no scale and finding the thresholds and d’ through Maximum Likelihood. The likelihood is easy enough to compute:

Here the responses k can run from 1 to N and t is a vector whose first element is 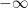

Geoff pointed out that this doesn’t seem to have been done in the literature (not through ML anyway), so I’m currently running some simulations using MCMC to verify how well behaved the likelihood is and how much more efficiently parameters of interest may be estimated (looking good so far).
Bill Geisler
Bill discussed natural image statistics and how to use this information both for machine learning-type applications and to verify whether observers behave optimally. He has written at length on his approach in a recent review, which you should read right now.
He showed several examples of this, which were really quite impressive. In the first, he used a seemingly toy example of estimating the luminance of a missing pixel based on neighbours. Using a model-free approach (creating a lookup table through binning), he showed how he could easily interpolate missing pixels using the 4 nearest neighbours along the horizontal and vertical axes. As it turns out, the optimal method is better than humans, but humans are better than, say, bilinear interpolation.
Applying this method in a real scene, he showed that he could beat state-of-the-art, computationally intensive methods in a superresolution task. Pretty amazing given that the method works through a freakin’ lookup table. They are apparently in the process of commercializing this technology and/or giving it away for free. See the last figure in their JOV paper (Geisler & Perry 2011), it rocks.
He then presented his PNAS paper (Burge & Geisler 2011) on defocus and a more recent effort which is quite similar, this time with binocular disparity. This latest one is in the process of being submitted.
