
I’ve been working on fitting a convolutional model of neurons in primary and intermediate visual cortex. A non-convex optimization problem must be solved to estimate the parameters of the model. It has a form similar to:
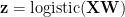


There are some shared weights to further complicate things, but the most salient features is that it’s a 3-layer ANN (input, hidden, output) with binomial loss and a sparseness penalty. This is a highly non-convex optimization problem. In addition, there’s so much data that it won’t fit into memory. One must thus use an “online” or “mini-batch” optimization method.
In convex problems second-order methods (conjugate gradient, quasi-Newton, plain jane Newton) are generally must faster than first-order methods (gradient descent with or without line search). After some initial successes with online gradient descent – it converged, albeit slowly – I figured I would try a second order method.
The main lesson I learned from this experience is that in a non-convex problem, the choice of optimization algorithm is an implicit parameter of the model – a hyperparameter. An optimization algorithm may converge faster than some other algorithm, but it might have a tendency to find crappy local minima. Thus, the choice of algorithm should be treated as a non-trivial hyperparameter that needs to be chosen, by, say, validation. This is a very different situation than convex optimization, where the choice of optimization method only affects the speed of convergence.
Stochastic gradient descent versus second-order methods
On my particular problem, I’ve tried:
- plain old stochastic gradient descent (SGD)
- online LBFGS
- careful second-order SGD
- homebrew block-scaled SGD with Bayesian updating of inverse Hessian with assumed structure (similar to this)
- homebrew block-scaled SGD with Monte-Carlo steps
Leon Bottou says that plain old SGD is hard to beat on this type of problem – a highly non-intuitive proposition. Indeed, on my dataset, plain old SGD worked better than second order methods: not only was it faster, but it tended to find better minima.
It took me a couple of weeks to figure out why this is. It is clearest with the block-scaled SGD with Monte Carlo steps. The idea is that instead of performing a plain SGD update:

I would instead use an update with different scales for the two sets of weights:
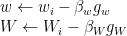
So, two learning rates instead of one. To determine these learning rates, I would solve an optimization problem every N iterations:

Because the Hessian for the betas tended to be exceedingly badly scaled, I instead used a stochastic search: I would nudge the betas by a small amount according to a random draw from a normal distribution (in log coordinates), and accept the update only if the new betas were better than the previous ones.
Surprisingly, I found that the betas tend to oscillate between two states, where one beta is large and the other is very small, as shown here:
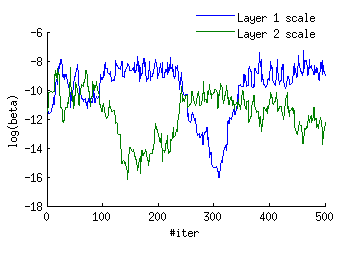
What that does is update one layer for several iterations, then the other, and so on.
Why? When the subunits of the hidden layer are in their linear regime, a decrease in the magnitude of the W weights can be compensated for by an increase in the magnitude in the w weights. Assume that the weights are small relative to the gradient in the first place. Then there’s an entire banana-shaped valley of pairs of 
Depending on initial conditions, then, either the first layer gets updated first, or the second layer gets updated first. Then one layer is over-adapted, and the algorithm switches to fitting the other layer. But the initially updated layer grabs a lot of the variance, so it becomes difficult to update the other layer. The fitting algorithm gets stuck with an undertrained first layer and an overtrained second layer, or vice-versa.
You could alleviate this by adding constraints on the model parameters – in fact, the sparseness prior on the output of the hidden layer places some constraints on the magnitude of the weights. The point I want to make here, however, is that in a non-convex optimization problem, it is very hard to parametrize the model in such a way that there are no pathological directions in the parameter space. This is one reason why ignoring the curvature information can help convergence.
What about the other algorithms? My homebrew scaled SGD with Bayesian updating of a constrained Hessian estimate had the same issue: the descent direction would vary wildly between updating the first and the second layer. Careful scaled SGD had the same problem: it sometimes preferred to update just one weight at a time.
Online LBFGS
Online LBFGS actually worked best out of all the second-order algorithms I tried. There are a number of properties which make this possible:
- By construction, the estimated (implicit) Hessian is positive definite
- There is a lambda parameter, which, when cranked up, forces the descent direction to stay close to the gradient direction
- When LBFGS fails – finds a non-descent direction – it automatically resets to the gradient descent direction via discarding the previous curvature information
- It does have a nasty tendency to find shallow local minima, but it converges very fast, so one can simply use more restarts
- It only has a couple of associated parameters, and they really don’t have much of an effect on convergence
That being said, it’s more expensive than SGD, since you have to monitor the progress and reset the curvature matrix whenever something weird happens to it, and you’ll need more restarts. Whether it’s worth it depends on the relative costs of evaluating the error function, its gradient, and how well your particular problem interacts with the assumptions of BFGS.
Scaled stochastic gradient descent
Therefore, even though your intuition, based on convex optimization, tells you that a second-order method must be better than plain old first-order SGD, in all likelihood for a non-convex problem a second-order method is probably only better than SGD by a small scalar factor, and quite possibly much worse. It should also be mentioned that SGD is extremely easy to implement and test.
Thus, after trying to beat the system, I’m using Leon Bottou’s advice: one scale for the first set of weights, another for the second set of weights, determined by trial and error on a small subset of the data. Note that this differs from the block scaled SGD algorithm I showed earlier because the learning rates are not adapted as the algorithm goes; they are fixed at the start of the iterations.
Since this is still expensive, a better approach could be to learn the scales via global Bayesian optimization. The method outlines in Snoek et al. (2012) looks very promising, and there’s some Python code to go along with it. If you have any practical experience with that, comment away.

One response to “Why second-order methods can be futile in non-convex problems”
[…] I discussed how I had no luck using second-order optimization methods on a convolutional neural net fitting […]