
The number game, which stems from Josh Tenenbaum’s PhD thesis, illustrates some important ideas about Bayesian concept learning. Here is a discussion of this in lecture notes from Kevin Murphy for reference. The basic setup is as follows: I give you a set of numbers from 1 to 100, and you try to guess another number in the set. For instance, I give you the numbers {4,8,64,2}. Intuitively, you might say another number in the set is 16, because that’s consistent with the concept that the set contains powers of 2.
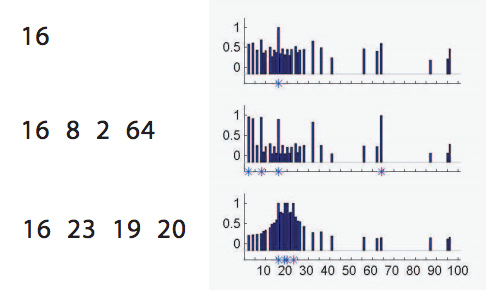
Now, it’s also the case that this example set contains only even numbers. Hence predicting 24 or 92 would be also pretty reasonable. Or we could say that the next number if 43, because the full underlying set is {4,8,64,2,43,57} – 6 uniform random draws from the range 1 to 100. How can we say with any authority what the next number in the set is, then?
Subscribe to xcorr and be the first to know when there’s a new post
We can pick the next element in the sequence as follows: evaluate the likelihood that a draw was from one of a finite set of concepts. Then, pick a number from this concept proportional to the probability that the concept was the one generating the original set. In other words, evaluate the probability that {4,8,64,2} was generated by one of a number of concepts – even numbers, odd numbers, powers of two, etc. – then pick a concept proportional to its posterior probability, and pick an element allowed by the concept uniformly at random. This is our guess of the next element in the sequence.
Here, we need to evaluate the posterior probability that a draw came from a given concept. Bayes’ theorem shows us that this probability is proportional to the likelihood of the draw under the concept times the prior probability of the concept.
Now, the likelihood of the draw under the concept is 0 if the concept is inconsistent with the draw – {4,8,64,2} and odd numbers, for example. If the concept is consistent with the draw, then probability will be higher, all else being equal, if the hypothesis set is smaller. This is what’s called the size principle: all else being equal, a draw {4,8,64,2} is more likely to have come from the set of powers of 2 rather than the set of all even numbers, simply because the set of powers of 2 is smaller than the set of even numbers.
This is one manifestation of Occam’s razor: a concept that can explain everything doesn’t explain anything.
What about the prior probability of a given set? Intuitively, we might say that simple concepts – the set of powers of 2, even numbers, etc. – are more likely than complex concepts – the set {4,8,64,2,43,57}. We can certainly estimate this prior probability empirically from the pattern of responses of humans in the empirical Bayes framework – as done in Josh Tenenbaum’s thesis. Is there a way to define an absolute concept of complexity of a concept, however?
The answer to this question is both illuminating and completely impractical. Algorithmic information theory defines Kolmogorov complexity, which is the number of tokens needed to describe a concept using a universal description language – a Turing machine, Python, assembly, lambda calculus, etc.
Of course, a concept might be much easier to describe in a given language than in another. If a language has a primitive for powers of two, then reasonably, it might only take one token to describe this concept in that language, but not in another. However, the theory of universal Turing machines tells us that the Kolmogorov complexity of a concept in one language is at most some constant plus the Kolmogorov complexity of this same concept in another language.
Why is this? Well, as long as both languages are Turing complete, it’s always possible to translate a program in the first language to a program in the second language by concatenating a universal emulator for the first language in the second language and a string corresponding to the program in the first language.
With the concept of Kolmogorov complexity in hand, it’s possible to define an absolute concept of prior probability for a given concept: the unnormalized prior probability of a concept is simply 2 to the power of the length of a program which produces the concept. So, for example, the concepts “even numbers”, “powers of 2”, and the set {4,8,64,2,43,57} can be expressed in Python via:
rg = xrange(100)
evens = [x if x % 2 == 0 for x in rg]
powers_of_two = [x if abs(math.log2(x) - round(math.log2(x))) < 1e-6 for x in rg]
weird_set = [x if x == 4 or x == 8 or x == 64 or x == 2 or x == 43 or x == 57 for x in rg]
You can see here that intuitively more complicated concepts take more tokens to express, which translates into lower prior probability. Neat!
Of course, this is highly impractical as a means of specifying prior probability. The biggest issue is that Kolmogorov complexity refers to the length of the smallest program which can produce the given concept. This length, however, is uncomputable. The hand-wavy version of this argument goes as follows: suppose I show you a program which can spit out a given concept. Does there exist an alternative program which is one token smaller which also produces the same concept?
To answer this question, I would have to evaluate all the valid programs which are one token smaller than the one I currently have, and check if any produces the required concept. One of the programs will, almost assuredly, get stuck in what looks like an infinite loop. Perhaps it will produce the required concept after long enough.
If only we had a function which can take an input program and decide whether this program will halt… you can see where I’m going with this – this function, famously, does not exist, and in fact producing a function which can compute the Kolmogorov complexity of a concept universally is equivalent to solving the halting problem.
So in terms of practical applications, setting the prior to a power of the Kolmogorov complexity is a dud. From a theoretical perspective, and from the standpoint of understanding Bayesian machinery, it’s quite a lovely theory, however. More on this subject in this lovely paper by Marcus Hutter on arXiv.

One response to “Turing machines, the number game, and inference”
[…] behind the judgements that seem to be reproducible amongst people. In this way, it’s similar to the Number Game, how you can get people to reliably complete sequences of numbers; in theory, any set is as good as […]