
Google Deepmind announced last week that it created an AI that can play professional-level Go. The game of Go has always been something of a holy grail for game AI, given its large branching factor and the difficulty of evaluating a position.
The new AI, called AlphaGo, has already won against the current European champion in October. It is scheduled to play in March against legendary player Lee Se-dol, widely considered one of the greatest players of all time, in a tournament reminiscent of the head-to-head between IBM’s Deep Blue and Gary Kasparov.
AlphaGo is a complex AI system with five separate learning components: 3 of the components are deep neural networks built with supervised learning; one is a deep neural net built with reinforcement learning; while the final piece of the puzzle is a multi-armed bandit-like algorithm that that guides a tree search.
This might appear overwhelming, so in this post I decompose this complex AI into 5 easiy pieces to help guide the technically inclined through the paper. An excellent introduction for the layman is here.
Finding the best moves

There are two underlying principles that allows AlphaGo to play professional-level Go:
- If you have a great model for the next best move. you can get a pretty good AI
- If you can look ahead and simulate the outcome of your next move, you can a really good AI
To attack the first problem, Deepmind trained a deep neural network – the policy network – to predict the best move for a given board position. They built a database of 30 million moves played by human experts and trained a 13-layer deep neural network to predict the next expert move based on the current board position.
This is similar to training a categorical deep neural network to classify images into different categories. The trained policy network could predict the best next move 57% of the time.
To strengthen this AI, they then pitted it against itself in a round of tournaments. They used policy gradient reinforcement learning (RL) to learn to better play Go. This lead to a markedly better AI – the RL network beat the vanilla network more than 80% of the time.
This is enough to create a decent go AI, and head-to-head matches against current state-of-the-art computer opponents showed a distinct advantage of the system- it won 85% of its games against the state-of-the-art open-source AI for Go, Pachi.
Going deeper
Training a network to play the very next best move at all times is surprisingly powerful, and rather straightforward, but it is not sufficient to beat professional-level players.

Chess and other adversarial two-player game AIs often work by looking at the game tree, focusing on the sequence of moves that maximizes (max) the expected outcome for the AI assuming the opponent plays his own best moves (mini); this is known as minimax tree search.
Minimax search can reveal lines of play that guarantee a win for the AI. It can also reveal when the opponent is guaranteed to win, in which case the AI abandons.
In other cases, however, it is simply too expensive to exhaustly search the game tree. The search tree grows approximately as 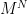
When the search goes too deep, the game tree is truncated, and a predictive algorithm assigns a value to the position – instead of assigning a value of +1 for a sure win and 0 for a loss, it might assign a value of +0.8 for a pretty sure win, for instance.
In chess, for example, one might assign a value of +1 to a checkmate, while an uncertain position would be scored based on the value of the pieces on the board. If we think that pawns have a value of +1, bishops +3, rooks +5, etc., and A stands for the AI and O for its opponent, the value of a position might be scored as:

It is not so straightforward to create such a value formula in Go: experienced players can often come to agreement on how good or bad a position is, but it is very difficult to describe the process by which they come with this evaluation- there is no simple rule of thumb, unlike in chess.
This is where the third learning component comes into play. It is a deep neural network trained to learn a mapping between a position and the probability that it will lead to a win. This is, of course, nothing more than binary classification. This network is known as the value network.
Researchers pitted the RL policy network against other, earlier versions of itself in a tournament. This made it possible to build a large database of simulated games on which to train the value network.
The need for speed
In order to evaluate lots of positions in the game tree, it was necessary to build a system which can evaluate the next best move very rapidly. This is where the fourth learning component come in. The rollout network, like the policy networks, tries to predict the best move in a given position; it uses the same data set as the policy network to do this.
However, it is rigged to be much faster to evaluate, by factor of about 1000 compared to the original policy network. That being said, it is also much less effective at predicting the next best move than the full policy network. This turns out to be not so important, because during the game tree search, it is more effective to try 1000 different lines of play which are not quite optimal than one very good line of play.
Sure, we lose money on every sale, but we make it up in volume.
Let’s put this into perspective. There is a policy network which predicts the next best move. Many different potential outcomes of the top moves are then evaluated based on the rollout network. The search tree is evaluated until a certain depth, at which point the outcome is predicted based on the value network.
Again, there’s a slight twist: in addition to the truncated value of a position predicted by the value network, it also plays out the position once until the very end of the search tree. Mind you, this is just one potential line of play, so the outcome of this full rollout is noisy. The average of the prediction from the value network and this full rollout, however, gives a better prediction of how good a position is than just the output of this value network by itself.
Putting it all together: tree search
The final piece of the puzzle is a very elaborate tree search algorithm. The previous best results in Go have been obtained with Monte Carlo Search Tree (MCTS). The game tree for Go is so large that going through the game tree to even moderate depths is hopeless.
In MCTS, the AI tests out positions by playing against a virtual opponent, choosing moves at random from a policy. By averaging the outcomes of thousands of such plays, it obtains an estimate of how good the very first move was. The important distinction between MCTS and minimax search is that not every line of play is considered: we look at the most interesting lines of play exclusively.
What do we mean by interesting? A line might be interesting because it hasn’t been well-explored yet – or it might be interesting because previous playthroughs seem to indicate a very good outcome. Thus, we want to balance exploitation of promising lines with exploration of other, poorly sampled lines.
This is, in fact, a version of the multi-armed bandit problem in the context of a tree, A very effective heuristic for the bandit problem is the upper confidence bound (UCB) policy. To balance exploration and exploitation at any given time step, UCB chooses the arm which has the highest upper confidence bound.
When faced with two arms which have the same expected reward, UCB chooses the one with the biggest error bar: we get a bigger boost in information from the most uncertain arm, all else being equal. On the other hand, faced with two arms with similar error bars, UCB chooses the one with the highest expected value: this has a higher probability of giving us a higher reward. Thus, UCB policy balances exploration and exploitation in an intuitive way.
The AlphaGo AI uses a variant of this heuristic adapted to trees known as upper confidence bound tree search, or UCTS. It explores branches of the tree – lines of play – which seemed the most promising at a given time step. The promise of a move is given by a mix of the evaluations from the policy, value, and rollout networks, plus a bonus proportional to the size of the error bar for this evaluation.
Much of the methods of the paper explain how this tree search can be done in an effective way in a distributed environment, which is a huge computer science and engineering undertaking… made a lot more tractable with Google’s resources and expertise, of course.
Conclusion
The AlphaGo AI is a hybrid system consisting of both deep neural networks and traditional Monte Carlo tree search. The neural nets allow the AI to examine at a glance what’s the next best move and what is the value of a position. It gives the AI a certain kind of intuition. The tree search, on the other hand, evaluates hundreds of thousands of potential outcomes by intelligently sampling from the game tree.
The advantage of such a hybrid system is that it scales with computational resources. The more CPUs you throw at the tree search, the better the AI becomes. This is not the case with a deep neural network, which becomes faster, not better, with more computational resources.
AlphaGo shows, once again, the promise of combining reinforcement and deep learning. These approaches could soon lead to intelligent autonomous agents, and perhaps even, as Demis Hassabis envisions, to general intelligence. These are truly exciting times.
Disclaimer: I work for Google, but was not involved in this research, and was not paid to write this introduction. All the info here is based on public information contained in the paper.
![]()
Silver D, Huang A, Maddison CJ, Guez A, Sifre L, van den Driessche G, Schrittwieser J, Antonoglou I, Panneershelvam V, Lanctot M, Dieleman S, Grewe D, Nham J, Kalchbrenner N, Sutskever I, Lillicrap T, Leach M, Kavukcuoglu K, Graepel T, & Hassabis D (2016). Mastering the game of Go with deep neural networks and tree search. Nature, 529 (7587), 484-9 PMID: 26819042

3 responses to “5 easy pieces: How Deepmind mastered Go”
Great write up! One quibble –
“This is where the third learning component comes into play. It is a deep neural network trained to learn a mapping between a position and the probability that it will lead to a win. This is, of course, nothing more than binary classification.”
If the network outputs a probability, then this clearly is not binary classification – is this a typo or am I misunderstanding things? Thanks.
Hi Andrew – this is not a typo, but I agree it could be explained better. When you train a logistic regression model to do binary classification, you give it training data consisting of tuples of the form .
The model does not actually directly predict a binary outcome (i.e. y=0|1) but rather the probability that a given example belongs to the positive class, p(y=1). It’s up to you to come up with an optimal threshold to binarize the prediction depending on your utility function.
In this case, we don’t care about binarizing the outcome; we actually care about the probability that a given example belongs to the positive class, p(y=1).
So what they do is train a deep net to do binary classification – with the same error function as you would use for logistic regression – and using the probabilistic prediction as the value of a position. Make sense?
Yes, I understood all this just fine – it just seemed like a misnomer to say a model that outputs a probability is doing binary classification since in my mind ‘binary classifier’ implies it outputs the classification itself (one of two possible outputs). But that’s really a matter of semantics -i’ve seen plenty of probability breakdowns for classifiers in papers, so I suppose I was being pedantic in my correction.