
Reverse correlation is a tried-and-tested nonlinear systems identification method to understand biological neurons. The idea is to open the black box that is a biological neuron by using random stimuli to probe how the neuron responds. We present a series of random stimuli to a sensory neuron. By averaging those that generated a response, we obtain the spike-triggered average. The spike-triggered average is equal to the weights of a linear filter that approximates the response of a neuron. Under this linearity assumption, it is also a neuron’s preferred stimulus.

Reverse correlation has fallen out of favour as people have graduated to more complex models (e.g. GLMs and deep nets) with more complex stimuli (natural scenes) to probe brain representations. However, the machinery underlying reverse correlation is making somewhat of an unexpected comeback in different corners of machine learning. This is something that I’m sure will surprise many machine learning people as well as neuroscientists. Digging deeper into these subfields yields some insights on improvements in nonlinear systems identification that we can take back to computational neuroscience. In this article, I discuss two of these ideas:
- evolution strategies, which are black-box optimization methods
- locally interpretable models, which are linearization models to open up black box models like deep neural nets
Before I dig into these methods, let’s dig into the theory behind reverse correlation so we can understand its deep structure.
The theory behind reverse correlation
Reverse correlation seemed pretty magical when I first encountered it! Put noise into a system, measure responses – out comes the kernel (?!). I ended up writing my PhD thesis on systems identification, so you’d think that by the time I graduated my thinking on this was solidified. In the years since, I’ve found that reverse correlation is actually pretty darn subtle, and I’ve developed a new appreciation for all the subtle aspects of the technique.
There’s a good exposition of the ideas behind reverse correlation in Franz & Schölkopf (2006). Let’s say that we are trying to characterize a nonlinear system that receives 

![\mathbb E [y|x] = f(\bold x) \newline \text{where } \bold x \in \mathbb R^N](https://s0.wp.com/latex.php?latex=%5Cmathbb+E+%5By%7Cx%5D+%3D+f%28%5Cbold+x%29+%5Cnewline+%5Ctext%7Bwhere+%7D+%5Cbold+x+%5Cin+%5Cmathbb+R%5EN&bg=ffffff&fg=000&s=0&c=20201002)
Then, under certain regularity conditions, we can write the mean response function of the system 
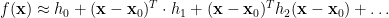
Note that the kernels 
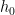
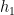
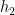
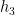
Misconception: the Volterra expansion is a Taylor expansion
The Volterra expansion is more general than a Taylor expansion: a Taylor expansion requires well-defined derivatives to every order, while a Volterra expansion does not. For example, the function 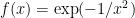

This subtle difference might seem like some nit-picking, but in practice, it is very important: discontinuous functions and stochastic functions can both be approximated with Volterra series. Biological Neurons are both stochastic and have potentially very sharp nonlinearities, yet we can still approximate them using a Volterra expansion.
The Wiener expansion is an orthogonalized version of the Volterra expansion.
To estimate the coefficients of the Volterra expansion, conventional reverse correlation first rearranges the Volterra expansion into an equivalent series of functionals, the Wiener expansion:
![f(\bold x) = \sum_i G_i[\bold x]](https://s0.wp.com/latex.php?latex=f%28%5Cbold+x%29+%3D+%5Csum_i+G_i%5B%5Cbold+x%5D&bg=ffffff&fg=000&s=0&c=20201002)
And imposes that these functionals are orthogonal to each other:
![\mathbb E_D[G_i(x)G_j(x)] = 0 \text{ for } i \ne j](https://s0.wp.com/latex.php?latex=%5Cmathbb+E_D%5BG_i%28x%29G_j%28x%29%5D+%3D+0+%5Ctext%7B+for+%7D+i+%5Cne+j&bg=ffffff&fg=000&s=0&c=20201002)
Here 
- Set
to the output of the Volterra kernel of order 0
- Set
to the output of the Volterra kernel of order 1, and back-project
- Set
to the output of the Volterra kernel of order 2, and back-project
This is the itty-bitty subtle bit: it turns out that the expectations of every order are straightforward to calculate when the data distribution ![\mathbb E[x^2] = \sigma^2](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5Bx%5E2%5D+%3D+%5Csigma%5E2&bg=ffffff&fg=000&s=0&c=20201002)

Since each functional are orthogonal over the data distribution, we can easily calculate them using an iterative procedure:
- Estimate the Wiener kernel
from the measured response
- Project the 0’th order functional out of
- Estimate the Wiener kernel
from the residual
, etc.
Estimating Wiener series with white noise means finding estimates that minimize sum-of-squares between prediction and measurement over the stimulus ensemble. We use a few shortcuts enabled by properties of white noise.
What does estimate mean in this context? Least-squares! To estimate the zero-order kernel, we have:
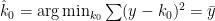
For the first-order kernel:

Here the approximate sign comes from the fact that with normally distributed data, 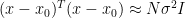

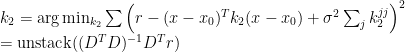
The columns of the matrix 



![k_i(j_1, j_2, \ldots j_i) = \frac{1}{i!\sigma^{2i}N} [y - \sum_{m=0}^{i-1} G_m(\mathbf x)] x_{j_1} x_{j_2} \ldots x_{j_i}](https://s0.wp.com/latex.php?latex=k_i%28j_1%2C+j_2%2C+%5Cldots+j_i%29+%3D+%5Cfrac%7B1%7D%7Bi%21%5Csigma%5E%7B2i%7DN%7D+%5By+-+%5Csum_%7Bm%3D0%7D%5E%7Bi-1%7D+G_m%28%5Cmathbf+x%29%5D+x_%7Bj_1%7D+x_%7Bj_2%7D+%5Cldots+x_%7Bj_i%7D&bg=ffffff&fg=000&s=0&c=20201002)
Where 
Is your head spinning yet? Mine sure was! Grinding through the kernels one by one makes a few things clear:
- Wiener-Volterra analysis isn’t magic. It’s orthogonal polynomial regression estimated through least-squares, with approximations that are enabled by the use of a very special distribution of the inputs, the normal distribution. This means that expectations of different moments can be analytically calculated.
- The Wiener kernel definitions change when you change the distribution of the input. This is because orthogonalization is dependent on the input distribution.
- The easy estimation of the kernels via backprojection and simple multiplication with cross-products of the inputs is lost when the input distribution is not normal.
The special properties of white noise were very important technically in 1958 when the series was proposed: the kernels could be estimated with very minimal computing resources. A memoryless accumulator is sufficient. Today, we’re no longer bound by these limitations, and we can do Wiener-Volterra analysis in a much wider range of contexts. Casting Wiener-Volterra analysis as polynomial regression fit via least-squares immediately opens up many extensions:
- Finding better estimates via the minimum variance unbiased estimator, that is, maximum likelihood
- Finding better estimates by better modeling the noise, for example, taking into account the Poisson nature of neural noise
- Generalizing to non-normally distributed ensembles of inputs, again using maximum likelihood
- Using alternative expansions, for example, cascades of linear-nonlinear filters (i.e. deep nets), fit with stochastic gradient descent
Remarkably, some of the ideas behind Wiener-Volterra theory – local polynomial expansion, probing stimuli at random – have made their way into far-flung machine learning methods. Let’s take a look.
Evolution strategies (ES)
Evolution strategies (ES) are a family of black-box, gradient-free optimizers for potentially non-differentiable functions. At the heart of most optimizers over continuous variables is the computation of the gradient. If the gradient is unaccessible because of discontinuities, or because it is very expensive to calculate, we can obtain a smoothed gradient via the ES method.
The setup is quite clever. We have a function 
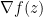
![\mathbb \nabla \mathbb E_\pi[f(z)]](https://s0.wp.com/latex.php?latex=%5Cmathbb+%5Cnabla+%5Cmathbb+E_%5Cpi%5Bf%28z%29%5D&bg=ffffff&fg=000&s=0&c=20201002)
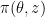
To compute the expected value, we expand it via its definition, and obtain:
![\nabla_\theta \mathbb E_\pi(z, \theta)[f(z)] = \nabla \int \pi(z, \theta) f(z) dz \newline = \int \nabla \pi(z, \theta) f(z) dz \newline = \int \nabla \log \pi(z, \theta) \pi(z, \theta) f(z) dz](https://s0.wp.com/latex.php?latex=%5Cnabla_%5Ctheta+%5Cmathbb+E_%5Cpi%28z%2C+%5Ctheta%29%5Bf%28z%29%5D+%3D+%5Cnabla+%5Cint+%5Cpi%28z%2C+%5Ctheta%29+f%28z%29+dz+%5Cnewline+%3D+%5Cint+%5Cnabla+%5Cpi%28z%2C+%5Ctheta%29+f%28z%29+dz+%5Cnewline+%3D+%5Cint+%5Cnabla+%5Clog+%5Cpi%28z%2C+%5Ctheta%29+%5Cpi%28z%2C+%5Ctheta%29+f%28z%29+dz&bg=ffffff&fg=000&s=0&c=20201002)
The last equality, which is also called the log-derivative trick, is derived from:
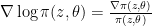
A neighbourhood which is often used in practice is the isotropic Gaussian centered at $\mu$ with a standard deviation $\sigma$. If we take a Monte Carlo estimate of the expectation, we find an approximation for the gradient as:
![\nabla \mathbb E[f] \approx \frac{1}{N} \sum_{1}^N \nabla_\mu \log N(\mu, \sigma^2) \newline = \frac{1}{N} \sum_{1}^N \frac{1}{\sigma^2} (z-\mu) f(z)](https://s0.wp.com/latex.php?latex=%5Cnabla+%5Cmathbb+E%5Bf%5D+%5Capprox+%5Cfrac%7B1%7D%7BN%7D+%5Csum_%7B1%7D%5EN+%5Cnabla_%5Cmu+%5Clog+N%28%5Cmu%2C+%5Csigma%5E2%29+%5Cnewline+%3D+%5Cfrac%7B1%7D%7BN%7D+%5Csum_%7B1%7D%5EN+%5Cfrac%7B1%7D%7B%5Csigma%5E2%7D+%28z-%5Cmu%29+f%28z%29&bg=ffffff&fg=000&s=0&c=20201002)
Notice this remarkable equation: this is exactly the response-triggered average with an isotropic gaussian stimulus ensemble. This reveals an unexpected link between reverse correlation and optimization: we can view reverse correlation as estimating an approximate gradient of the response function of a neuron.
The response-triggered average tells us how we should change a stimulus locally to increase the response of the system.
Taking ES to reverse correlation

The unexpected link between reverse correlation and optimization opens up a lot of different avenues. For instance, we could adapt ES to maximize the response of a neuron in a closed-loop fashion. This strategy has the advantage of being trivial to compute and highly intuitive (i.e. no complaints from reviewer 2 about the method being inscrutable).
ES is also embarrassingly parallel, which has been used to good effect in the context of reinforcement learning – OpenAI showcased ES with 1024 parallel evaluations. We could consider evaluating the gradient of a neuron’s response function in parallel with several other neurons – perhaps in a different animal, in a different lab – and optimize for a stimulus that maximizes the sum of the responses. Indeed, we don’t have to focus on maximizing just the mean response of a neuron: we can maximize the diversity of responses, their dimensionality, etc. This works as long as the metric that we’re measuring is a scalar function of the measured responses.
ES comes in a variety of different flavours that aim to increase the efficiency of the method. Two of the most popular variants are:
- CMA-ES (Covariance-matrix-adaptation). This takes the derivative of the neighborhood with respect to the covariance of the normal distribution, in addition to its mean. Thus, the covariance stimulus ensemble is tweaked to capture the largest dimensions of descent.
- NES (Natural evolution strategies). This uses natural gradients rather than gradients, which naturally deals with rescaling of the axes.
Both of these more efficient variants could be applied to find preferred stimuli in a population of neurons.
Finally, because the ES objective is a Monte Carlo estimate, we can import many of the tricks from the variance reduction literature to increase the efficiency of reverse correlation. For example, we can use control variates or use stratified sampling strategies. My favourite trick to increase the efficiency of estimation: pairing every stimulus with its negative. With this trick, the mean of the realized stimulus ensemble is exactly the mean of the distribution. This antithetic sampling can, in some circumstances, increase the efficiency of the estimation of the preferred stimulus.
Locally interpretable models
There’s another area where the ideas underlying reverse correlation have recently come together: locally interpretable models. Suppose that we have a complex black-box model that we are trying to better understand. This black box model can be, for example, a deep neural network. We can locally approximate this complex function with a simpler, local expansion. This local explanation does not capture all the subtleties of the model, but it can reveal insights that are useful for humans that want to understand the model.
Black-box models are good for predictions by machines. White-box models are good for understanding by humans. LIME transforms black-box models into locally white-box models.

In general, we try to find a model 


Here 



Several choices are possible for 
- a GAM
- a decision tree
- a linear model
If we choose no penalty for complexity and choose a linear model class, our model and error function is equivalent to reverse correlation and evolutionary strategies. This highlight something that’s underappreciated about reverse correlation:
The spike-triggered average is a simplified, locally valid explanation for how a neuron works. While complex models like deep nets can capture more of the variance in the data, the goal in reverse correlation is different: explaining neurons to humans.
Taking LIME to reverse correlation
An underappreciated fact about reverse correlation is that the size of the neighbourhood around which we’re linearizing is arbitrary and that different neighbourhoods will lead to different estimates.
Many articles have documented that receptive fields appear to change with changing stimulus ensembles, for example natural vs. artificial stimuli. However, this has been explained in terms of a special, adaptive response of neurons to natural image statistics; for instance, that they increase the degree of feedforward inhibition they receive. In fact, the same phenomenon could happen simply because we’re measuring a nonlinear function, so that its locally linear expansion depends on the stimulus ensemble.
Many of the parameters of the probing distribution are arbitrary:
- the size of the neighborhood (big vs. small)
- the shape of the neighborhood (isotropic Gaussian vs. non-isotropic vs. natural stimuli)
- the center of the neighborhood (gray image or another reference)
Some of the most interesting applications of nonlinear systems identification have manipulated each of these factors. For example, by shifting the center of the neighbourhood to an appropriate anchor point, we can locally linearize quadratic responses (i.e. complex cells) by choosing an appropriate anchor point. This is the idea behind Movshon et al. (1978), where the line weighting function of a complex cell is found by using another line in the center as an anchor:

There are some other excellent nuggets in the LIME paper that could serve us well. For instance, they suggest using a maximally diverse ensemble of examples (SP-LIME) to illustrate the functioning of the models to humans. A similar idea was used in Cadena et al. (2018) to visualize diverse features that triggered large responses in early stages of a deep neural net around an anchor point (invariant or equivariant features).
Finally, we can have our cake and eat it too: we can fit very complex models of neurons that explain much of the variance in sensory systems using deep nets, and visualize how these models work using locally linear explanations. It sounds a little silly to fit a model to a model, but it’s a technique that has been used fruitfully both to explain sensory neurons and to compress neural networks.
Conclusions
Both ES and LIME use local linearization strategies similar to reverse correlation to explain complex black box function. From ES, we learn that the reverse correlation estimate gives us a local approximation for the gradient, which can be used as a starting point for closed-loop experiments. From LIME, we see that we can perform reverse correlation centered around different neighbourhoods, yielding different results. By following these new research trends in machine learning, we can find innovative ways of opening the black boxes that are biological neurons.
