
The Gallant lab have just published a new paper in Current Biology about decoding visual activity in fMRI evoked through natural movies. TryNerdy has a very high level overview of the paper. Here I’m more interested in the nitty gritty computational/statistical details.
The idea is to train an encoding model using fMRI responses during natural movies. Then the goal is to decode what natural movies were presented to an observer based on a second set of fMRI responses (see movie above). Importantly, the second set of fMRI responses was not used during training. Furthermore, there is no overlap between the presented stimuli in the training and decoding sets. This is a pretty tough test of the ability of the encoding/decoding models to extrapolate.
The goal of decoding is to infer the stimulus s that drove a response r. From Bayes’ theorem, 
The likelihood 
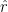



There’s a lot of headroom in choosing X, but the authors chose I think a pretty interesting representation. Rather than focusing on the static content of the movies, the representation actually encodes the localized motion energy in the movies extracted with a standard energy model (above, B). There’s extra channels for 0 temporal frequency so that static patterns are represented in addition to motion. If only static patterns are represented however, the quality of the reconstruction is quite a bit poorer. So it’s really the motion energy that’s driving a lot of the reconstruction ability, rather then the static content, and I think there’s some interesting implications for the role of motion in object recognition.
w represents the weights of the linear encoding model, and are estimated using the training data (above, A). Each voxel is assigned a separate encoding model, representing its sensitivity to position, speed, orientation, as well as its hemodynamic response. There’s a lot of weights, so the regression is regularized through an L1 penalty
The prior 
In this case, the posterior probability of stimuli is discrete, 
Taking the expected value of the posterior didn’t work too well either; the authors tell us that this typically averaged over only two or three video clips. So instead they averaged over the top 100 stimuli. Not too sure what this corresponds to in terms of implicit loss, but usually rank-based measures are quite robust. So you can probably think of it as a robust measure of the bulk of the posterior.
The results are pretty convincing; have a look at Jack’s page on the subject for more example videos.
![]()
Shinji Nishimoto, An T. Vu, Thomas Naselaris, Yuval Benjamini, Bin Yu, & Jack L. Gallant (2011). Reconstructing visual experiences from brain activity evoked by natural movies Current Biology : 10.1016/j.cub.2011.08.031

4 responses to “Decoding fMRI activity evoked by natural movies”
[…] used the same videos as their reconstruction (“mind-reading”) 2011 Current Biology paper, which if I remember correctly were scraped from YouTube. Tagging this data must have taken […]
[…] Primeiramente, eles desenvolveram um modelo de codificação movimento-energia para funcionar com o fMRI para refinar a informação limitada fornecida pelos lentos sinais de blood oxygen level dependant (BOLD), refletindo as contribuições separadas dos neurônios subjacentes quando relacionados com a atividade hemodinâmica. A percepção de movimento têm se mostrado muito difícil de representar a partir de uma perspectiva computacional. Se você é versado em estatística e gostaria de ler mais sobre o algorítmo deles, veja aqui. […]
[…] Primeiramente, eles desenvolveram um modelo de codificação movimento-energia para funcionar com o fMRI para refinar a informação limitada fornecida pelos lentos sinais de blood oxygen level dependant (BOLD), refletindo as contribuições separadas dos neurônios subjacentes quando relacionados com a atividade hemodinâmica. A percepção de movimento têm se mostrado muito difícil de representar a partir de uma perspectiva computacional. Se você é versado em estatística e gostaria de ler mais sobre o algorítmo deles, veja aqui. […]
[…] Don’t miss a look at the clips if you have not done so already. (there is a link above) This is not mind-reading but it is an definite achievement. Those interested in the mathematical nitty gritty should read xcorr’s posting. […]