
State space methods are a very broad class of methods to analyze temporal data. At its most basic, you assume that your temporal data is generated by a model with underlying parameters. The parameters are time-varying, and usually it’s assumed that the temporal variation is generated through Markovian dynamics. That is, at every time-step, the parameters of the model are determined only by their previous value and a transition probability. Hidden Markov Models (HMMs) and the Kalman filter are canonical examples of state-space models with discrete and continuous states, respectively.
There’s an excellent review by Paninski et al. (2009) on the use of state-space models with continuous hidden variables for neural data analysis. The key point that the authors try to bring across is that you really don’t need the standard computational machinery of Kalman filters in terms of recursive filtering to work with state space models. Rather, you can use standard Generalized Linear Models (GLMs), embed Markovian dynamics in them, and use standard Maximum Likelihood/Maximum A Posterior (ML/MAP) methods to figure out the model parameters.
This is a really neat trick, because GLMs for neural data analysis have been intensely studied, there’s software for them, and a bunch of extensions and generalization have been developed for them.
Let me give you an example application. It’s straightforward to use a GLM to estimate receptive fields. Now add Markovian dynamics to the receptive field parameters. What do you get? A GLM that estimates time-varying receptive fields! You can use this to study learning, remapping, adaptation; the applications are endless.
The simplest case
Now the math might at first look a little daunting, but to emphasize, if you understand GLMs then you understand state-space GLMs. It’s very instructive to look at the simplest state-space GLM, which contains only one time-varying parameter:


Here, the neuron follows a Poisson process, with a time-varying drive which has Markovian dynamics. Intuitively, if we estimate w(t), we will get a smoothed version of the log of the measured firing rate. So the purpose of this very simply state-space GLM is to obtain a smoothed estimate of a PSTH.
I loaded up some spike data, which looks like this:
Now let’s try and estimate w(t) using standard GLM methodology. Now, we can rewrite y(t) and 


Where 

You will recognize this as a simple penalty based on first-order differences between next-neighbour weights. It’s just a plain vanilla smoothness penalty. Thus:
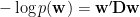
Where D is a second order difference operator.
Inference in Matlab
It’s possible to infer the parameters of this model using any software for GLMs with quadratic penalties, including my own Matlab package. I loaded up a 60s PSTH of neural data (y, 5ms bins) from one of our experiments, which looks like this:

Now let’s infer w for different values of the precision 
X = speye(length(y));
P = spdiags(ones(size(y))*[-1,1],[0,1],length(y)-1,length(y));
Q = P'*P;
figure(2);
for ii = 1:3
glmopts.family = 'poissexp';
results = glmfitqp(y,X,Q*3^ii,glmopts);
subplot(3,1,ii);
plot(exp(results.w))
end
And here are the results:

It’s really not more complicated than that. Here’s a small portion of the weights w(t) with the corresponding spike train on top:

You can see that each spike gets transformed to a double exponential shape. That makes sense; if you applied a recursive filter of order 1 (say, with filtfilt) this is exactly the kind of behaviour you would expect.
Extrapolation and interpolation
Now let’s try and extrapolate and interpolate to understand how the thing works. To do this, we can simply set the elements of X corresponding to the time points we want to censor to 0. In that case, the fit will be completely insensitive to the weights corresponding to these time points. Thus the model will rely entirely on the prior to determine the value of the extrapolated or interpolated weights. First, extrapolation:
Xa = X; Xa(end/2+1:end,:) = 0; results = glmfitqp(y,Xa,Q*3,glmopts); plot(results.w(end/2-100:end/2+100));

Extrapolated weights get set to the last value before the cutoff. Makes sense, since with first order dynamics the weights only depend on the last value, and the transition probability is symmetric around this value. As for interpolation:
bounds = [-40,-25,-10];
for ii = 1:3
Xa = X;
Xa(end/2+bounds(ii):end/2+25,:) = 0;
results = glmfitqp(y,Xa,Q*27,glmopts);
subplot(3,1,ii);
plot(diff(results.w(end/2-100:end/2+100)));
hold on;
plot([100,100]+bounds(ii),[-4.5,-2],'k',[125,125],[-4.5,-2],'k');
axis tight;
end

The interpolation is purely linear, which is expected if the probability distributions on both sides of the interpolation range are Gaussians with similar variance.
Of course, it’s possible to change the dynamics, and intra/extrapolation will change accordingly. For example, if we set 
Static parameters
It’s also possible to mix dynamic parameters and static parameters. For example, this smoother might not capture well the behaviour of the neuron at short time scales, because of the refractory period. We can add a time lagged version of y to account for the refractory behaviour:
y = histc(ts,0:.001:10); y = y(1:end-1); X = speye(length(y)); P = spdiags(ones(size(y))*[-1,1],[0,1],length(y)-1,length(y)); Q = P'*P; glmopts.family = 'poissexp'; glmopts.algo = 'newton'; yl = y(max(bsxfun(@plus,(1:length(y))',-1:-1:-7),1)); results = glmfitqp(y,[X,yl],blkdiag(Q*27,speye(7)*.01),glmopts); plot(results.w(end-6:end))
And the results:

Conclusion
Embedding state space dynamics in GLMs is pretty easy. For real applications you’ll probably want to use a less generic GLM implementation than the one I used here to save some computation time. The paper contains many more examples of the utility of state-space GLMs.

3 responses to “State-space GLMs for neural data: a simple example”
Thanks Patrick! It would be wonderful if there was a package, like Victor’s Spike Toolbox, to allow these methods to see greater use amongst the Neuroscience community.
Although the Kalman filter can be used in real time, state-space methods in general are useful in offline analysis scenarios, and that’s mostly what I’m interested in. Discrete state-space models are useful whenever you believe there are multiple discrete states a neuron (or neurons) can be in and it switches between these states in time. So you could use them to analyse phenomena like binocular rivalry, for example. I’ve seen it used to analyze the sequence of states in the mushroom body of insects following an odor. Another example is spike sorting, where you assume the neuron is either in the no-spike or in the spiking state.
Continuous states are useful whenever you believe some aspect of the neuron changes slowly in time in a continuous manner. As a rule of thumb, wherever your natural inclination would be to smooth things in time or analyse data in short time windows you can use continuous state space models instead. A number of applications involve inferring the input to a neuron. With one input you get a smoother for the firing rate (above). With two inputs you can tease out the excitatory and inhibitory inputs to a neuron. You can look at learning, adaptation, or any number of nonstationarities. You could for example look at how the firing rate changes as a function of trial number following a manipulation. Or track neuron waveforms as a function of time to verify the stability of your recordings and compensate for their lack thereof.
As a non-mathematically inclined neuroscientist, what does this allow me to actually do with my data post-hoc; is the utility of this mostly to do with real-time and multi-neuron recordings?