
Multi-unit activity (MUA) is usually derived by high-pass filtering a raw wideband signal, thresholding with a low threshold or rectifying, and subsequently using a low-pass filter. The intuition I think is correct, in that spikes from far away neurons will cause transient blips in the wideband signal which can be amplified by thresholding.
The usual methods, however, seem very hacky; to the best of my knowledge, there are no methods for estimating the MUA grounded in sound statistical theory. This seems like a waste, since the MUA might be able to capture properties of large scale populations of neurons; unlike the LFP, the source of the MUA is well understood.
I’ve been experimenting with different methods of estimating the MUA through Bayesian methods. MUA differs from single unit activity in that instead of focusing on clustering spikes, the problem is in detecting the spikes. In fact detection is so difficult that giving binary spike/no-spike judgements is probably a lost cause; it appears more appropriate to use continuous judgements.
In other words, if s corresponds to a spike train, spike sorting single unit activity focuses on solving the problem:
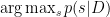
Where D is the data. For MUA processing, however, it seems a more appropriate objective is to determine the expected probability of spikes:
A simple model for spike identification
Let’s start by writing out a simple model for a whitened wideband signal y containing stereotyped spikes w:

This simply states that the signal is the sum of stereotyped spikes plus iid Gaussian noise. The spike trains themselves can be given iid Binomial priors:

It’s possible to give a beta prior to 

Given these assumptions, how can we estimate 
For the spike trains, Gibbs sampling thus reduces to comparing the probability of the data with the spike added to the currently estimated spike train versus no spike added. Let’s say that we are looking at the current time point t, and the current spike train is s_i. Then we have to do the following:
- Set
- Compute
- Compute
. This involves taking the difference between the residual sum-of-squares with the spike added versus without the spike added.
- Set
with probability
.


The algorithm proceeds by following these steps for every time point for a given number of iterations. I simulated some data containing a few spikes and a lot of noise and it looks like this:

I then ran the Gibbs sampling algo. The following shows the simulated spike train as a function of Gibbs sampling iteration:

Notice how each vertical line relates to what appears like a positive blip in the wideband signal a few samples after.
Unfortunately the Gibbs sampler does not mix well. For example at the top you can see that 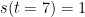

Yet despite this, the algorithm does seem to identify spikes reasonably efficiently. The correlation between the spike train and the estimated probability of a spike is > .9. In the next article, I’ll modify the Gibbs sampler so that it samples many time points in a single shot, and most of the difficulty will go away.

One response to “Spike identification through Gibbs sampling #1”
[…] Last time, I demonstrated how to use Gibbs sampling to obtain an estimate of the probability of spikes at different time points given a wideband signal. Unfortunately the method I proposed suffered from long correlation times. In this post I expand upon the previous method to obtain a practical method for identifying spikes. […]