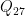I wrote earlier about a recent paper by the Pillow lab which uses priors optimized through the evidence (aka marginal likelihood) to estimate spatially and frequency-localized receptive fields. It seems that evidence optimization might be seeing something of a revival as a technique for estimating model hyperparameters. I just posted an update on my GLM with quadratic penalties package to use this technique.
Specifically, we can assume that the prior in a GLM is given by 
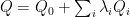
Then the hyperparameters 

The precision is sufficiently flexible to accommodate interesting model structure. For example, in the poster that Theo and I presented at SFN, I used it to track functional connectivity as a function of time. Functional connectivity can be estimated by using the firing patterns of other neurons as inputs to a GLM whose output is the target neuron. Each functional connection is defined by 3 parameters, corresponding to Laguerre basis functions. Only a handful of possible connections will turn out to be significant; therefore, it’s natural to impose a penalty on the magnitude of each group of 3 parameters. Now if in addition we let these parameters change over time, it’s also possible to add one smoothness penalty per group of 3 parameters. In total, we had 28 cells, hence 27 inputs for a given cell; thus,