
Is it better to use natural or synthetic stimuli to estimate receptive fields? Vargha Talebi & Curtis Baker (who’s on my committee btw) have a new paper out in J Neurosci suggesting that RFs estimated with natural images generalize better to other stimulus ensembles than white noise or flashed bar stimuli. They mapped area 18 simple cell receptive fields with these three stimuli ensembles. They show a pretty stark difference in the quality of cross-ensemble predictions (fit with one ensemble, predict on another) depending on what ensemble was used in the first place, with RFs fitted with natural images generalizing better (their Figure 10, below). This also follows when examining predicted spatial frequency and orientation tuning curves.

This result is quite surprising, especially since visually the receptive fields look quite similar when mapped with different ensembles. While I think this doesn’t change the main conclusions of the paper, I have a few technical issues with the comparisons. I think it’s important when comparing predictions made with different stimulus ensembles that the comparisons be made apples-to-apples, meaning one stimulus set is not given an undue advantage. The receptive fields where estimated through linear regression, followed by fitting the nonlinearity. The linear regression was regularized through early stopping.
Now this is not the form of early stopping often used in conjunction with boosting, but rather in conjunction with gradient descent with (if I’m not mistaken) a fixed step size. In this case minimization of the mean-squared error (
- Initialize w = 0
- Until cross-validation score becomes worse:
- compute g = X’*(y-X*w)
- set w = w – alpha*g for some small alpha
Now the optimal maximum-likelihood estimate is of course given by 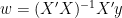

On the other hand, if the stimulus ensemble is spatially correlated, as with natural images, the initial gradient will be not be in the direction of the maximum likelihood estimate, since X’X is not a multiple of I. In fact, the gradient in this case will point towards a direction corresponding to highly spatially smooth weights. As the number of iterations increase, gradient descent will slowly correct for this. Thus, in this case gradient descent with early stopping will implement an implicit prior on the smoothness of the weights, and would thus be similar to an explicit smooth prior with a tunable hyperparameter that is slowly decreased as the number of iterations is increased.
Of course smoothness in the spatial domain is a perfectly reasonable assumption, and certainly a more efficent one than a weight decay prior. So in that sense I think the natural images data is given an unfair advantage (unless there’s some technical detail I’m missing).
Another technical issue I have is that the nonlinearity is fit only at the end. There are technical conditions guaranteeing that this will lead to unbiased RF estimates (elliptical symmetry I think), which none of the stimuli ensembles follow. I think it’s possible there’s some sort of interaction between the nonlinearity and RF that would change the RFs if they were fit simultaneously with the nonlinearity, and that this affects the different stimuli ensembles differently. Anita Schmid & Jonathan Victor presented a poster at this SFN which showed different RF estimates depending on stimulus ensembles, and if I remember correctly, the changes in RF were shown to be explainable in terms of an interaction between RF and static nonlinearity.
My intuition is that the two issues would tend to cancel each other somewhat, but it’s still a concern. My final qualm is that since there are contrast gain control mechanisms involved, you should refit the nonlinearity when predicting on other stimulus ensembles, since I don’t think it’s reasonable to think that the threshold and slope for this new ensemble will have the same effective value.
In any case, I’m sympathetic with the conclusions, and I think the results are pretty convincing nonetheless.

2 responses to “Natural vs. synthetic stimuli for estimating receptive fields”
I’m pretty sympathetic to the conclusions, too, but I wonder if this has a very simple explanation. Is this just because short bars have high spatial correlation, white noise has zero spatial correlation, and natural scenes are ‘somewhere in between’? In which case you would expect a stimulus set that is in a space somewhere between the other two sets to do a better job of predicting the outcome of the other two?
(If it discussed this in the paper, I apologize, I’m at home and my proxy is being funky so I can’t look at it.)
That could well be the case. However, I think natural images have actually stronger spatial correlations than the short bar stimulus that they are using. The result for white noise vs. natural images isn’t very surprising to me; white noise probably doesn’t drive the cells very well, and that makes it difficult to get good predictions out of this stimulus. As for short bars vs. natural images, the largest difference they found is in their respective ability to estimate the spatial frequency selectivity of the cells. This is probably related to the relative spatial frequency content of both stimulus types.