
I’m thrilled to announce that our paper, Hierarchical processing of complex motion along the dorsal visual pathway, has been published in PNAS.
In this work, we looked at the response properties of neurons in area MST (the medial superior temporal area). MST neurons are part of the dorsal visual pathway; they are strongly selective for motion. They have huge receptive fields (up to about a quarter of the visual field). They receive a large part of their input from area MT, where most neurons have smaller receptive fields which are strongly selective for translation motion.
Unlike MT, however, MST neurons are often tuned for combinations of motions called optic flow patterns. Some MST neurons, for example, are exquisitely selective for patterns of expansion or rotation. Furthermore, this selectivity is often invariant to the position of the optic flow pattern within the receptive field of an MST neuron.
Optic flow tuning
This selectivity has been documented many times over the years. We found similar tuning to complex optic flow in our dataset. We showed translation motion in 8 different directions, at 9 spots in the receptive field. We did a similar thing for spirals, which include expansion, contration, clockwise and counterclockwise rotation and their intermediates, and finally we did the same for deformation motion. Here’s an example of tuning curves for the 3 different types of optic flow at a single position in a receptive field:

We replotted this data as color coded tuning mosaics. The mosaics highlighted in green below are color coded representations of the information shown in the tuning curve data above. For each optic flow type, each mosaic represents a tuning curve at a given position inside the receptive field. This cell shows some tuning for downwards motion, as well as some expansion tuning, and deformation tuning.

Here’s a cell which has highly invariant tuning to expansion and downwards motion:

Here’s one which is highly invariantly tuned to rotation:

And here’s a final cell with exquisite tuning for expansion:

Although MST receives most of its input from MT, neurons in MT don’t show this type of invariant optic flow tuning; rather, they’re tuned mostly for translation. It remained unclear how MST neurons achieve their exquisite selectivity for optic flow patterns, namely, what kind of computations MST neurons perform that allow them to extract information from optic flow patterns.
Systems identification
We focused our attention on understanding the relationship between MST and its dominant input from area MT. We attacked this problem using systems identification methods. We developed a stimulus which consists of an aperture containing moving dots. The aperture moved slowly around the screen. The dots within the aperture moved according to a varying optic flow pattern. Here’s what it looks like:
You’ll notice that the stimulus varies between translation, rotation, expansion, contraction, and non-rigid deformation motions. We recorded from area MST while this stimulus was presented, and tried to determine how responses from MST neurons could be created by combining the responses from MT neurons.
MT neurons are well studied, so we used a descriptive model of MT neurons that replicated their tuning to motion. Specifically, modeled MT neurons had Von Mises direction tuning, log-Gaussian speed tuning, and isotropic Gaussian receptive field profiles.
We started off with the assumption that MST responses are generated by a simple linear-nonlinear-Poisson cascade. The stimulus is processed by a filterbank of MT neurons. The MT inputs are weighted and summed. This is then sent through an rectifying output nonlinearity, which determines the firing rate of the cell. Responses are generated from this by a Poisson process.
This seems like a perfectly reasonable starting point. As formulated, the MST model is a Generalized Linear Model that can be fit with standard GLM methods.
However, this model is not that obvious to fit, because the MT filterbank has to be pretty large to account for the range of position, direction, and speed tuning that you find in MT. Even at a relatively low sampling resolution, say 12×12 in space, 3 speeds, and 8 directions, that’s still several thousand MT neurons, and as many weights that need to be fit.
So you need to reign in the number of parameters in the model. Here I used boosting (specifically, gradient boosting) to impose an implicit sparseness prior on the model parameters, with early stopping determined by 5-fold cross-validation.

To assess the quality of fit, I attempted to predict the responses of the cells to the tuning curve stimuli based on the fit to complex optic flow. For some cells this worked reasonably well, and an example is shown in B (same as the first cell I presented). For most cells it failed pretty badly like the cell shown in C (same as the second cell I showed).
What seemed to be happening is that the responses to translation were over-estimated while the responses to complex optic flow were underestimated. When translation stimuli are presented over one of the subunits, it responds strongly. Meanwhile, complex optic flow will tend to drive several subunits, but only weakly because the stimulus changes rapidly from position to position. Yet MST neurons respond strongly to complex optic flow, which hints that they prefer several subunits being driven weakly over one subunit being driven strongly.
This data thus provides strong hints that MST neurons perform nonlinear integration over their inputs, and that this integration is AND-like or multiplicative-like. This is actually straightforward to model in the GLM framework; the combination of a compressive nonlinearity following the input and an expansive output nonlinearity approximates a multiplicative interaction (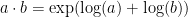

Indeed, if you allow a power-law nonlinearity between the MT stage and the integration stage, you find that:
- The predictions become qualitatively better; in particular the gain of the cells for complex optic flow is much better modeled, as you can see for the example cell above
- The quality of predictions becomes much better for the vast majority of cells
- The optimal power-law nonlinearity almost always has an exponent lower than .5, hence it’s strongly compressive
MST receptive fields
Now that we were confident that we had a good model of MST, we could reconstruct the receptive fields of these cells. Here’s several examples. The cell in A is the same as the second cell I showed above, while the cell in B is the very first cell I presented. The others are all selective for expansion, but they have very different receptive field organizations. It’s really quite amazing the diversity of RFs that you find. From this we concluded that MST neurons are probably not detectors of canonical optic flow fields per say, but are really detectors of a small number of motion directions.

In that sense, I think MST is a lot like V4. V4 neurons respond remarkably well to non-Cartesian gratings, which are analogues in the orientation/spatial frequency domain of canonical optic flow patterns (Gallant, Connor et al. 1996). Connor’s later work showed that V4 neurons are better understood as selective for combinations of orientations (curvature tuning). I think we’re seeing essentially the same thing here in the motion domain.
Mechanisms
We showed strong evidence that MST performs AND-like nonlinear integration over its MT inputs. The form of the model suggests a series of plausible mechanisms, where some compressive mechanism acts over the MT input, which is then linearly integrated and transduced by the spiking nonlinearity of an MST neuron to a firing rate.
The question is, what is this compressive mechanism? A divisive mechanism at the level of MT could give the right compressive effect. Some manifestations of this purported divisive mechanism include: self-normalization (à la Rust et al. 2006), contrast normalization, tuned center-surround antagonism and untuned center-surround antagonism.
From a mathematical perspective, all these things can be expressed as follows: the output of an MT subunit is divided by the summed output of a pool of MT subunits with a given tuning. If this pool is spatially compact and untuned, you get contrast normalization; if it’s big and tuned, you get tuned center-surround antagonism.
So we fit 125 different models for each cell, corresponding to 5 different normalization strengths, 5 pool sizes, and 5 pool tuning strengths. We reasoned that if the compressive nonlinearity is unambiguously created in MT, we would find that the optimal parameters were similar for each cell, and correspond to a well-known mechanism. Rather, we found that the majority of cells preferred strongly tuned normalization pools of small spatial extent. But this is not “real” normalization: each MT cell is normalized by itself, which is mathematically equivalent to a pure compressive nonlinearity.
So to put this in perspective, we gave these neurons these extra degrees of freedom corresponding to well-documented normalization mechanisms, and they rejected them, giving us back the same answer: it’s just a compressive nonlinearity! So we tried some more: maybe the antagonism is not divisive but subtractive. Maybe it’s spatially inhomogeneous (see the many papers by Guy Orban on inhomogeneous surrounds in MT) . Maybe it’s a combo of a spatially homogeneous subtractive mechanism and a compressive nonlinearity. We tried a bunch of different things, and despite all this, we got back the same answer every time: it’s just a compressive nonlinearity.
Thus, our work shows that the necessary compressive effect is probably not inherited from MT; it’s created de novo in MST. It could be created by synaptic depression, or maybe by normalization within MST (as in the canonical circuit of Poggio).
On that subject, I will mention a very recent paper (came out a week ago) by Bölinger and Gollisch published in Neuron that found AND-like selectivity for homogeneous stimuli in salamander retina. There’s some really nice ideas there, including how to measure AND-like integration directly, and some pharmalogical manipulations to isolate the mechanism (they found something that sounds very Poggio-like rather than synaptic depression).
Conclusion
We started with a very poor mechanistic understanding of MST, and through systems identification, we built a model that accounts for a good proportion of response variance in MST. This allowed us to determine that MST neurons have multiplicative-like interactions within their receptive fields. We ruled out many MT-based mechanisms for this effect. We can now visualize MST receptive fields and show the full spectrum of receptive field organization within this area.
In a final simulation, we used the explicit models that we built to show that the nonlinear response properties that we found are useful in extracting object motion. Thus, it could well be that MST in not only useful to determine ego-motion, but also to determine object motion.
The study raises many questions which will be addressed in later work. Bolinger and Gollisch in their latest paper show us a route towards studying multiplicative interactions within MST and other areas more directly. The study also emphasizes the need to better understand spatial integration within MT, which is something that Dan, Chris, Yuwei and Liu Liu are already working on. Finally, I hope this will convince somebody to look at complex motion processing further along the dorsal visual stream. Poggio had a paper that showed how the dorsal visual stream could process biological motion ten years ago, and no one has done anything about it; I think it’s a shame.
Credits
Please excuse the gratitious use of I instead of we and vice-versa. I did the analysis, and co-first-author Farhan Khawaja did the recordings. Dan supervised the computational aspects, and of course Chris deserves all the credit: it was his idea, his equipment, and most of the nice prose is also his. I would like to thank Maurice Chacron and Curtis Baker for reading and commenting on the manuscript.

One response to “Hierarchical processing of complex motion”
[…] So the MNI press office picked up our recent PNAS article: […]