
In the last post, I discussed using an extended Kalman filter to decode place cells, based on the algorithm published in Brown et al. (1998). The results looked pretty good. EKFs are certainly better than population vector approaches that don’t consider the sequential nature of the decoding task. The fact that the path of the rat must be continuous should be certainly be used in the decoding process.
However, extended Kalman filters are rather inflexible. They only deal with systems which are quasi-linear, and they are a bit ad hoc. Place cells are not especially good system to use EKFs, since the rate of the cells is a highly nonlinear function of the position.
A flexible alternative to the EKF is the particle filter, which is a sequential Monte Carlo method. The idea behind the vanilla version of the particle filter called sequential importance resampling (SIR) is very simple. As in other Monte Carlo methods, the probability distribution of the current state (at time t – 1) is represented by a set of samples. These samples are called particles. To obtain the probability distribution of the state at the following time point, it suffices to propagate the probability through these equations:


The second equation is cake; since the probability distribution is represented by samples, one only needs to propagate the samples through the transition distribution. This typically involves nudging the position of the particles by random amounts determined by the prior. Then:
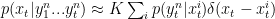
An estimate of the current state is then given by the expected value of this probability distribution. Now eventually the weights for most particles will go to zero, hence a resampling step is required. If a distribution is given by a weighted sum of delta functions, then it can be sampled by taking multinomial draws corresponding to the weights. If you decide to do this at every time point, then you get the SIR particle filter with unconditional resampling, which is the form of particle filter used in Brockwell, Rojas and Kass (2004; Recursive Bayesian decoding of motor cortical signals by particle filtering). There’s fancier forms of particle filters available, which involve using better proposal distributions, but I’m waiting for my ReBEL license (a Matlab toolkit) to try them out.
I tried both the EKF and particle filter using the same simulation method as in the previous post. Here’s an example decoded path using the EKF:
 And the same with the particle filter:
And the same with the particle filter:

You’ll notice that the reconstruction is much more reliable for the particle filter (MSE of .11 and .07 in the x and y direction versus .19 and .16 for the EKF). Repeating these simulations 100 times, I found a mean MSE of 0.095 in both directions for the particle filter (with 1000 particles) and .13 for the EKF (the median MSE was 10-20% better). So the effect is certainly large enough to matter in practice, especially if the errors are not random but last for a large number of time samples.
The EKF seems to get stuck for long periods of time after rapid movements. My intuition here is that in some circumstances the posterior of the state has some weird shape with multiple local minima. The EKF, which performs a local search, gets stuck in a local minimum for some number of time steps, until by chance a path is created towards the global minimum. Indeed, you can plot the state distribution given by the particle filter, and frequently you’ll see bimodal distributions like this one:

Now Brown et al. mention that sometimes their algorithm doesn’t track sudden movements very well. This could be due to this issue of the decoder getting stuck in a local minimum, but it could also be due to a failure of the model to capture the super-Gaussian changes in position from frame to frame. Indeed, they show in Figure 3 that the density of position changes is not well captured by a Gaussian, and suggest a Laplacian distribution might be more appropriate. I simulated paths where the velocity was given by $v=(r\cos(\theta),r\sin(\theta)$ where r had an exponential distribution with mean .03 and $\theta$ had a uniform distribution.
I attempted to decode the place cells with three models: EKF with incorrect transition probability, particle filter with incorrect transition probability, and particle filter with correct transition probability. Here the EKF error increased marginally from .13 to .14, while the particle filter with both correct and incorrect transition probability got MSEs of .095. From this simulation, it appears that changing the prior barely has an effect on the ability to reconstruct the stimulus. This is counter-intuitive, and would suggest that the reconstruction is mostly driven by the likelihood term rather than the prior term. I don’t really buy this result, and I’d like to try the same with real data. It does point towards the idea that the problem with the EKF is not so much its inability to capture the super-Gaussian nature of the transitions but really the dumber problem that the posterior has a weird shape and it just can’t deal with that well.
In any case, the particle filter is quite a bit simpler to program than the IEKF, it’s faster, and it’s more flexible. I’d like to try it on the CRCNS hippocampal dataset by Buzsáki whenever I have the chance.
Here’s the script I used to run the particle filter:
function [xs,Ws,particles] = pfDecoder(Y,params,W)
%Here I implement the method of Brockwell, Rojas and Kass (2004)
nparticles = 1000;
%Draw from the initial state distribution
xtildes = randn(nparticles,2);
xs = zeros(size(Y,1),2);
Ws = zeros(size(Y,1),2,2);
particles = zeros(size(Y,1),nparticles,2);
Wsqrt = W^(1/2);
%Main loop
for ii = 1:size(Y,1)
%Step 2: compute weights according to w = p(y|v_t=xtilde)
ws = computeLogLikelihoods(xtildes,Y(ii,:)',params);
%Normalize weights
ws = exp(ws-max(ws));
ws = ws/sum(ws);
%Step 3: importance sampling
idx = mnrnd(nparticles,ws);
S = bsxfun(@le,bsxfun(@plus,zeros(nparticles,1),1:max(idx)),idx');
[idxs,~] = find(S);
xtildes = xtildes(idxs,:);
particles(ii,:,:) = xtildes;
%Step 3.5
xs(ii,:) = mean(xtildes);
Ws(ii,:,:) = cov(xtildes);
%Step 4: Propagate each particle through the state equation
xtildes = xtildes + (Wsqrt*randn(2,nparticles))';
if mod(ii,100) == 0
fprintf('Iteration %d\n',ii);
end
end
end
function lls = computeLogLikelihoods(xtildes,y,params)
%Predicted rate for each neuron given Gaussian RF models
xdelta = bsxfun(@times,bsxfun(@minus,xtildes(:,1),params(:,1)'),1./(params(:,3)')).^2;
ydelta = bsxfun(@times,bsxfun(@minus,xtildes(:,2),params(:,2)'),1./(params(:,4)')).^2;
loglambdas = bsxfun(@plus,-.5*(xdelta+ydelta),params(:,5)');
lambdas = exp(loglambdas);
%Compute negative log-posterior
%First part is due to likelihood of data given position, second part is
%the prior prob. of positions
lls = -(-loglambdas*y + sum(lambdas,2));
end

2 responses to “Using a particle filter to decode place cells”
Dear Doctor Patrick,
I have read your fancy code about using particle filter to decode place cells. Have you tried them on CRCNS hippocampal dataset by Buzsáki?
Actually recently I have been working hc2 dataset. I was kind of stuck on performing decoding on grid cells. I think I have been doing well on encoding stage. I am wondering if you have time, so that we could discuss more. Thank you very much!
Best,
Skyler
Hi Skyker,
I haven’t tried on hc2 but I’m sure you could get it to work. My advice would be to try the code on data that you know will work first, that is, simulated data in a similar format, with a similar firing rate and of a similar length than the real data. Once you understand how that works, then you can try it on the real data. Oftentimes, the first few cells you try it on will have noisy properties, and it can be hard to figure out if your code isn’t working because the data is bad or because your code is wrong. Doing it in steps will help you isolate the problem. Cheers!