
Early convolutional neural net (CNNs) architectures like the Neocognitron, LeNet and HMAX were inspired by the brain. But how much like the brain are modern CNNs? I made a pretty strong claim on Twitter that the early visual processing is nothing like a CNN:
In typical Twitter fashion, my statement was a little over-the-top, and it deserved a takedown. What followed was a long thread of replies from Blake Richards, Grace Lindsay, Dileep George, Simon Kornblith, members of Jim DiCarlo’s lab, and even Yann LeCun. The different perspectives are interesting, and I’m curating them here.
My position, in brief, is that weight sharing and feature maps – the defining characteristics of modern CNNs – are crude approximations of the topography of the early visual cortex and its localized connection structure. Whether this distinction matters in practice depends on what you want your models to accomplish – I argue that for naturalistic vision, it can matter a lot.
Subscribe to xcorr and be the first to know when there’s a new post
Background
There are several defining characteristics of modern CNNs:
- Hierarchical processing
- Selectivity operations (i.e the ReLU)
- Pooling operations
- Localized receptive fields
- Feature maps
- Weight sharing
Where did these ideas come from?
Hubel and Wiesel (1962) described simple and complex cells in the cat primary visual cortex. Simple cells respond best to a correctly oriented bar or edge. Complex cells, on the other hand, are not sensitive to the sign of the contrast of the bar or edge, or its exact location. They hypothesized that simple cells are generated by aggregating the correct LGN afferents selective for light and dark spots, followed by the threshold nonlinearity of the cells. Complex cells were hypothesized to be generated by pooling from similarly tuned simple cells. They later expanded these ideas: perhaps first-order and second-order hypercomplex cells are created by the repetition of the same pattern. Thus, hierarchy, selectivity, pooling and localized receptive fields were all hypothesized to be taking place.
Fukushima (1980) adapted many of these ideas in a self-organized hierarchical neural network called the Neocognitron. In the S-layers, neurons weight the input from previous layers via localized receptive fields, followed by a ReLU nonlinearity. In C-layers, inputs from the previous are pooled linearly, followed by a sigmoid.

The Neocognitron also introduces what may be the defining features of modern CNNs: parallel feature maps (here called planes) and weight sharing. This is most clearly seen in the selectivity operation for S-layers, which is a convolution over the set of local coordinates, followed by a ReLU:
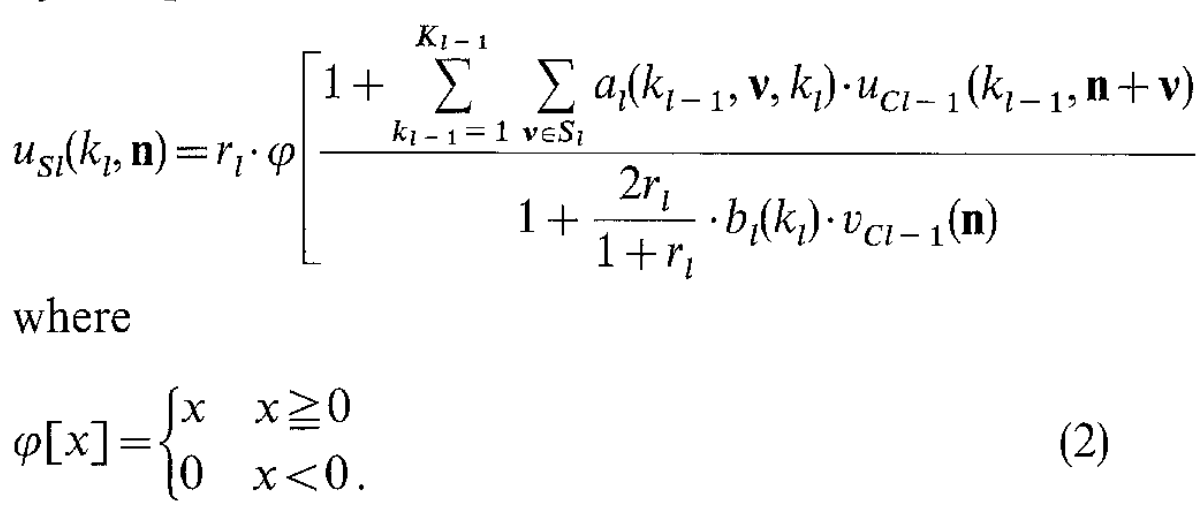
The reason behind the introduction of parallel feature maps and weight sharing is not very clear in the original paper, and in fact, in section 3 the paper casts doubt on how realistic these assumptions are as a model of vision:
One of the basic hypotheses employed in the neocognitron is the assumption that all the S-cells in the same S-plane have input synapses of the same spatial distribution, and that only the positions of the presynaptic cells shift in parallel in accordance with the shift in position of individual S-cell’s receptive fields. It is not known whether modifiable synapses in the real nervous system are actually self-organized always keeping such conditions. Even if it is assumed to be true, neither do we know by what mechanism such a self-organization goes on.
So why introduce these features at all?
Topography conquers all
Fukushima however links localized receptive fields with the idea of localized topography:
[…] orderly synaptic connections are formed between retina and optic tectum not only in the development in the embryo but also in regeneration in the adult amphibian or fish
This is one of the enduring facts of visual neuroscience: inputs from the retina are preserved topologically as they make their way to the LGN, V1, and onwards to the extrastriate cortex. Visual angle and log radius are mapped from the retina to V1 in development, guided by chemical gradients. The progression of the maps reverses as we go up the visual hierarchy (in fact, areas are defined by this very reversal in direction). What’s remarkable is how precise the topography is: Hubel and Wiesel estimated that in the primary visual cortex, neighbouring cells varied in receptive field center by less than half a receptive field.

There’s another fact of life in cortex, which is that horizontal wiring is expensive. If a neuron integrates from localized inputs, and those inputs are retinotopically organized, that neuron will have a localized receptive field. If you assume that the synaptic pattern is localized and random then for every cell, there must be other similarly tuned cells somewhere else in the visual field. My postdoc advisor Dario Ringach introduced a model (2004) for how simple cells in primary visual cortex can occur from such sparse localized connections.
That covers feature maps. However, if the input statistics to primary visual cortex are stationary, then a self-supervised criterion could refine a randomly initialized V1 feature map, effectively letting the input do the weight tying – a subtle point brought up by Blake Richards.
Non-stationarities at the large scale
I hope to have convinced you that the link between CNNs, first introduced by Fukushima, and early visual processing in the brain is quite subtle. Whether a CNN is a good or a bad model of early visual processing depends on what phenomenon we care to model. If we’re talking about core visual recognition in the parafovea – which is what the majority of the quantification comes from – the match is quite good. At larger spatial scales, however, I would argue that the match is compromised by two facts.
First, spatial resolution is not constant as a function of space. A CNN on a Cartesian grid doesn’t scale with eccentricity. This issue has received some attention lately, and foveating CNNs are starting to be considered – see this recent paper from Arturo Deza and Talia Konkle for example.
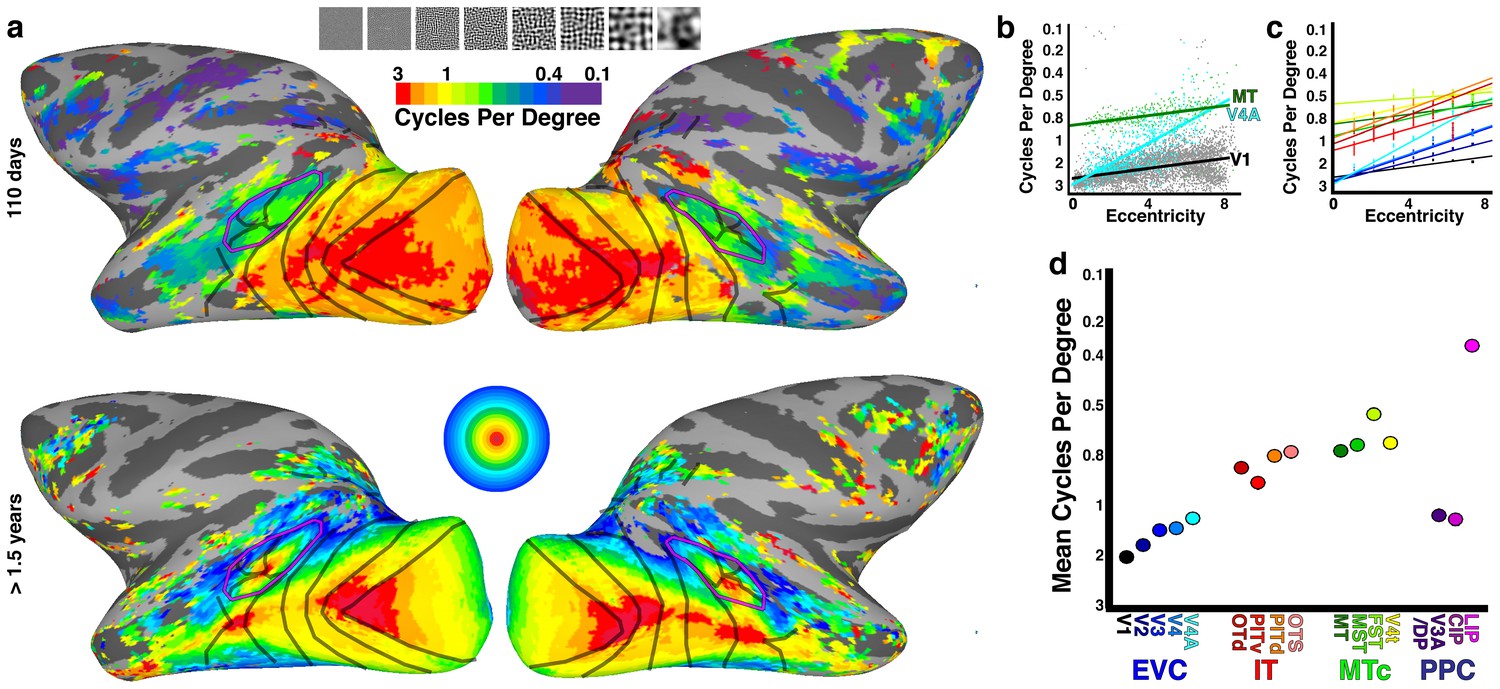
Secondly, the eyes foveate on interesting targets – e.g. faces – which means that statistics are highly nonstationary different as a function of space. The ground looks very different from the sky. Hands tend to be in the lower half of the visual field, and numerous visual areas have only partial maps of the visual field. There’s an overrepresentation of radial orientations, more curvature selectivity in the fovea, no blue cones in the fovea, etc.
Here’s a picture to illustrate this. If VGG19 is a good model of primary visual cortex, then it follows that maximizing predicted activity in primary visual cortex could be done by maximizing an unweighted sum of VGG19 subunits, a la DeepDream. If you do that for layer 7 of VGG19, you get the picture on the left. However, we can use fMRI to estimate a matrix, via ridge regression that maps VGG19 to an fMRI subspace, and then optimize a weighted sum of VGG19 subunits, giving us the picture on the right. This image highlights some of the known spatial biases in primary visual cortex – shifts in preferred spatial frequency as a function of eccentricity, radial bias, and curvature bias in the fovea – which are not apparent in an unweighted VGG19. So at the very least, the brain’s image manifold is rotated and rescaled compared to the VGG19 image manifold.


Margaret Livingstone has a very interesting line of research (talk here) highlighting the close link between spatial biases and the development of object and face recognition modules in high-level visual cortex. More generally, if we’re interested in how vision is organized for action – ecological vision in the tradition of Gibson – then whether a network has captured, e.g. the fact that the bottom half of the visual field has very different affordances than the top half matters. If you applied an unsupervised criterion to learn features from natural images without weight sharing, those features would vary quite a bit across space – unlike in a CNN. This point was also raised by Dileep George.
Weight sharing is not strictly necessary
LeCun (1989) demonstrates the use of backpropagation to train a convolutional image recognition network. There’s a beautiful figure that highlights the effect of adding more and more constraints, in particular in going from a fully-connected 2-layer network (net2) to a high-capacity convolutional neural net (net5):
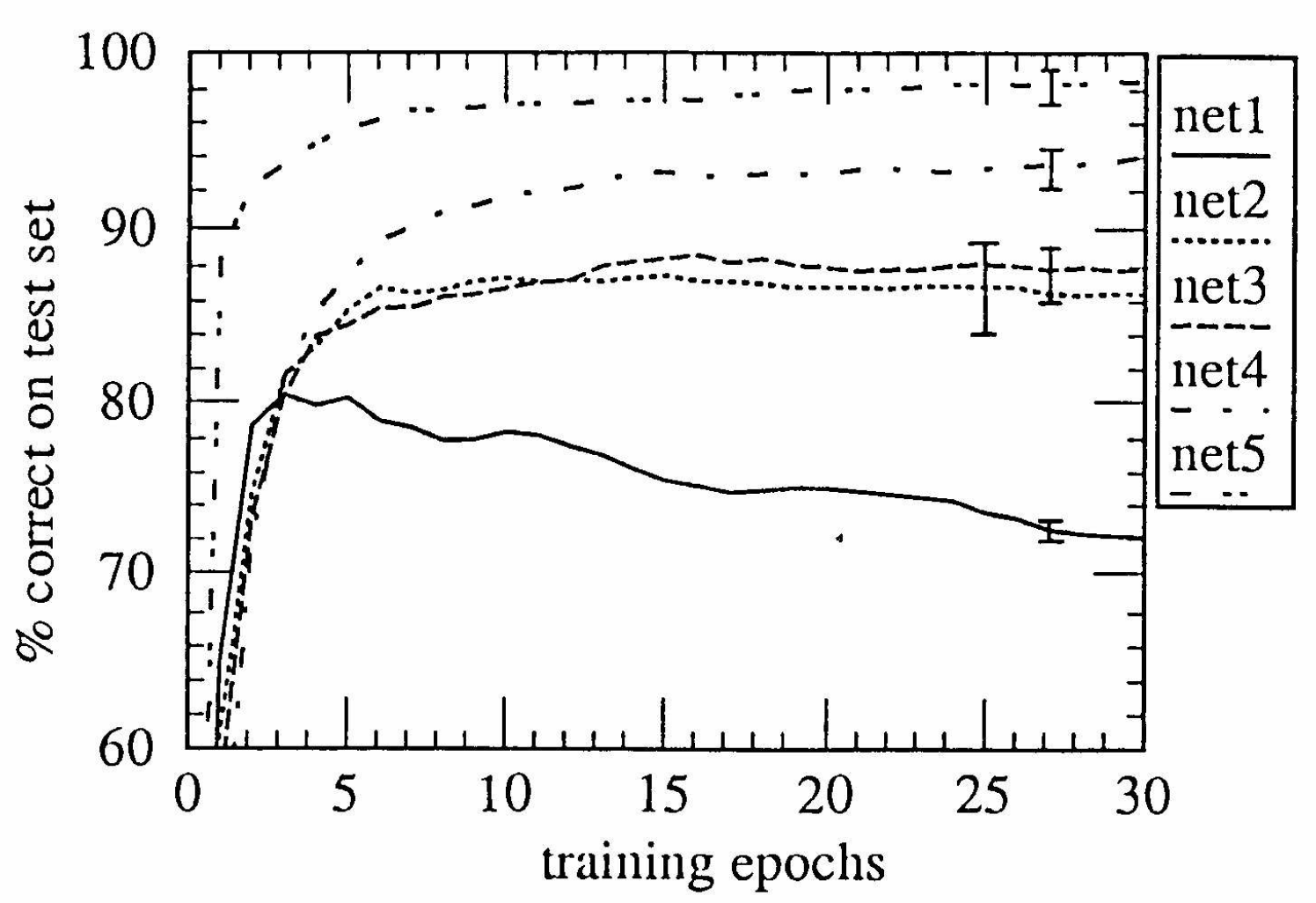
LeCun (1989) clarifies that weight sharing is a clever trick that decreases the number of weights to be learned, which in the small data limit is practically important to obtain good test set accuracy. We are a long way from 1989 in terms of dataset size, and unsupervised learning could learn untied feature maps, as pointed out by Yann LeCun in the Twitter thread. But would currently existing benchmarks favour ANNs-with-local-receptive-field-but-untied-weights?
The leaderboard is the message
Let’s turn back to the claim that early visual cortex is like a particular CNN. As Wu, David and Gallant (2006) put it:
an important long-term goal of sensory neuroscience [is] developing models of sensory systems that accurately predict neuronal responses under completely natural conditions.
Brain-Score is an embodiment of this idea – benchmark, across many different datasets and ventral stream areas, the ability of many different CNNs to explain brain activity. The leaderboard is pretty clear that the VGG19 architecture outperforms alternatives in explaining average firing rate – even when these alternatives are better at classifying images in ImageNet. That’s an interesting finding – VGG19 is shallower and has larger receptive fields than more modern CNNs, so perhaps its performance on this benchmark is because of that.
Grace Lindsay pointed out that:
[…] when the results were first coming out that trained convolutional neural networks are good predictors of activity in the visual system some people had the attitude of “that’s not interesting because obviously anything that does vision well will look like the brain”
What’s interesting is that we now have architectures that solve object recognition which are very different from CNNs, namely visual transformers (ViT). They are architecturally different from brains, and while they perform well on ImageNet, they underperform in predicting single-neuron responses. So now we have a clear example of a disconnect between ImageNet performance and similarity to the brain, and that strengthens the claim that core object recognition is like a CNN.
So on the one hand, the data from BrainScore says that CNNs are the best models of core object recognition, yet there are pretty stark ways in which early visual processing is unlike a CNN, some of which I’ve mentioned already, others which have been highlighted in Grace Lindsay’s excellent review.
Would Brain-Score, in theory, rate better a model which respects the distinction between excitation and inhibition (Dale’s law)? That seems unlikely since there are no cell type annotations in the datasets. Would it rate better a foveated model or one that doesn’t have weight sharing? Again, unlikely, since as Tiago Marques points out, for technical reasons, most datasets are taken in the parafovea. In any case, the metric used to score the models is rotation invariant, so it wouldn’t be able to tell these cases apart. As Simon Kornblith points out, choices of metrics are not falsifiable. The right approach for choosing metrics is the axiomatic one, as demonstrated in Simon’s CKA paper: the modeller or the community decides what the right metric is based on design criteria that represent what they think is interesting about the data.
Does that mean we should ignore Brain-Score? No! I really like Brain-Score – I wish there were many more Brain-Score-like leaderboards! Comparing on lots of datasets prevents cherry-picking – there is robustness in the meta-analytic approach. What I’m excited about is the possibility of Brain-Scores – a constellation of leaderboards that benchmark different models according to rules which match on modeler’s interests. I’ve been involved in proto-community-benchmark efforts like the neural prediction challenge and spikefinder before, and the technological barriers to running such a leaderboard have been lowered by commoditized cloud infra. The value proposition is also becoming clearer, and I am excited to see more of these efforts pop up.
Conclusion
In brief:
- Convolutional neural nets assume shared weights
- This assumption is not valid at large spatial scales
- Large spatial scales matter if you care about naturalistic foveated vision
- It’s a useful assumption in the low-data regime, which we’re not in
- The current benchmarks are not sensitive to this issue
- It’s possible and desirable to create new benchmarks which are sensitive to this, and I hope to do that in the future!

One response to “Is early vision like a convolutional neural net?”
[…] wrote last year about an apparent mismatch between convolutional neural nets (CNNs) and the visual cortex: brains […]