
2022 has come and gone and we’ve learned a lot about how the brain is – or isn’t – like an artificial neural network. There isn’t a single journal or venue that focuses exclusively on neuroAI so the literature is spread across preprint servers, conference proceedings and the occasional prestige journal. As an end-of-year treat, I challenged myself to gather all papers in neuroAI that were published this year and tell you all about them. I skimmed through ~130 abstracts and I read a few dozen to find the best, most influential, and most interesting, and extract this year’s zeitgeist. A systematic review this is not; rather, these are my humble musings on the state of neuroAI. Hope you learn something useful!
What counts as neuroAI anyway?
NeuroAI is the intersection of AI and neuroscience, but that’s a little vague. I couldn’t find a good comprehensive survey of neuroAI that delineated what is and isn’t neuroAI, and I wanted to circumscribe my search. So I enumerated all the different flavours of neuroAI that I’ve seen in the wild and placed them in a two-dimensional rubric:
- On the horizontal axis, one defines the researcher’s “home turf” or “application area”: AI (left) or neuroscience (right). Usually, papers import ideas from an outside field to their home field. Do you want to understand how to the brain works, or do you want to make better AI?
- On the vertical axis, one defines whether one is motivated by applications (”doing useful things”, “engineering”, etc.) at the top vs. curiosity driven at the bottom.
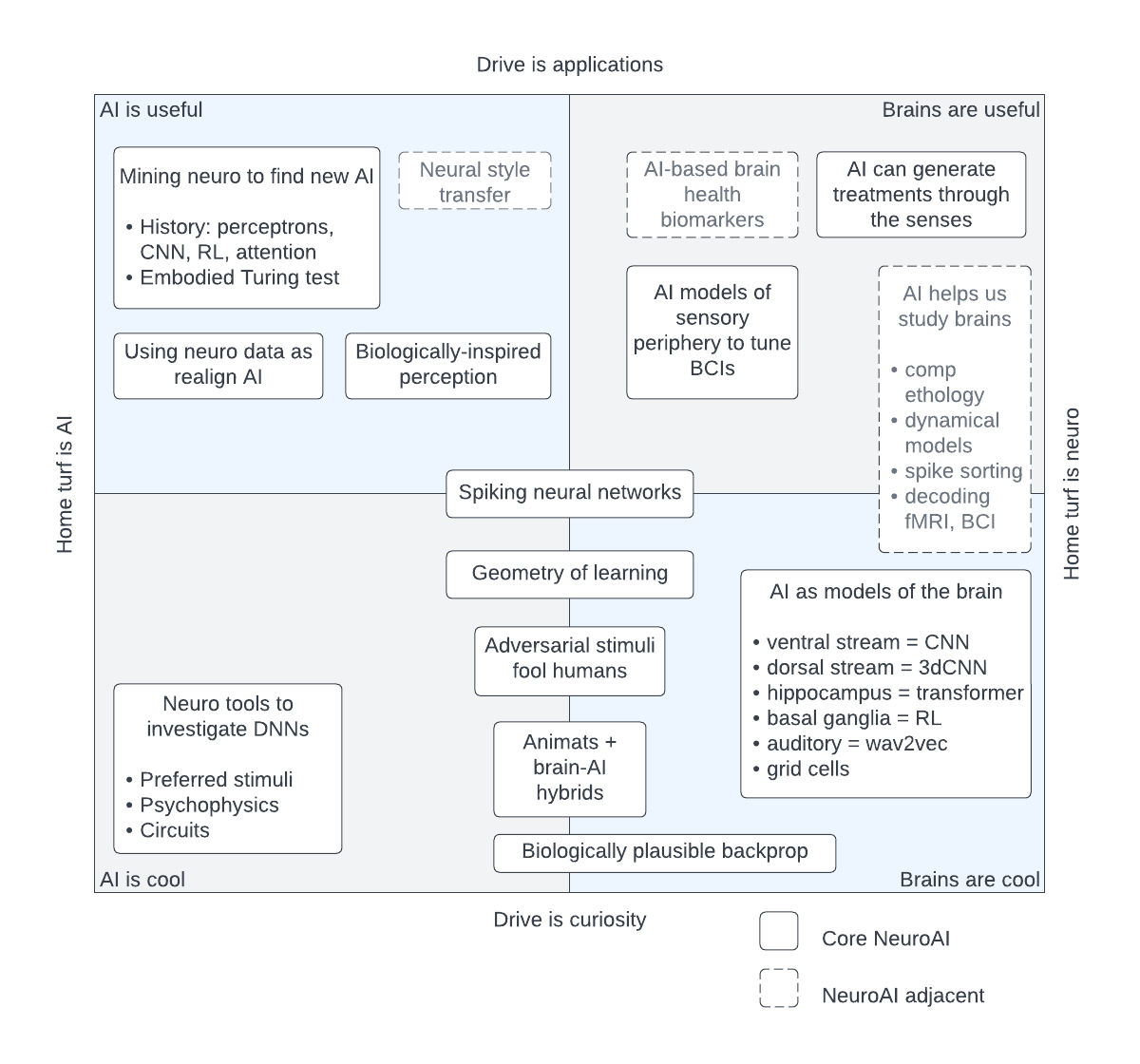
Within this framework we can identify major flavours of neuroAI: mining neuroscience to find ways of making AI better ends up in the top left corner, while using artificial neural nets as models of the brain ends up in the bottom right. We also find less common lines of research, for example animats: brain-AI hybrids, at the bottom. The diagram also identifies big chunks of research that use AI in an instrumental fashion to study brains; these fall outside of core neuroAI. For instance, automatic spike sorting or biomarkers for brain health fall outside of core neuroAI in this classification. I’ve found this diagram useful in explaining what our field is to researchers outside of our field and to understand how different pieces of research fit together. It’s still a work-in-progress so please do let me know if you have better ideas.
Even with this fairly circumscribed definition of neuroAI, it turned out a lot of neuroAI research was published this year! I turned to Twitter and Mastodon to ask people for their favorite publications, then I looked through my Twitter bookmarks, then I searched on Google Scholar for people that I knew. I dedupped, removed papers outside of core neuroAI, then applied a completely arbitrary “does this pique my interest?” filter, and ended up with ~130 publications, excluding abstracts from the SVRHM workshop at NeurIPS which may get its own separate blog post later. To sort through this, I tried using sentence embeddings + a UMAP to visualize the results, but eventually resorted to the tried and true method of clustering by hand. Let’s start with the big ideas.
Big ideas about the future of neuroAI
Two whitepapers came out to define neuroAI research programmes: ambitious, decade-long, multi-lab research endeavours to solve big questions. The two are not strictly in opposition – they share a couple of co-authors – but they nevertheless represent different visions of where to take neuroAI.
Subscribe to xcorr and be the first to know when there’s a new post
The neuroconnectionist research programme
Doerig et al. (2022) argue from the bottom right corner of the neuroAI diagram. They define neuroconnectionism as modeling the brain with artificial neural networks (ANNs) in a goldilocks zone of biological detail. There’s a healthy dash of philosophy of science thrown in: it’s fruitful to model the brain with ANNs because it helps us uncover deep truths about how the brain works. The core of the theory is not falsifiable, but the belt can be.

Findings where ANNs differ from the brain in key ways, e.g. adversarial attacks, are envisioned as opportunities to change the belt of the theory. This process can continue until the core theory stops being useful as a scientific paradigm. I think this stance is a default stance of many in the field, and it is aggressively neutral: we do neuroAI because we think that brains are cool and we should study them and we now we have a useful tool to do so, so let’s do that!
Toward Next-Generation Artificial Intelligence: Catalyzing the NeuroAI Revolution
Tony Zador and a who’s-who of AI people and computational neuroscientists argue from the top left corner of the neuroAI diagram: let’s learn about the brain so we can solve AI. Current generation AI is specialized; even a modest mouse shows far more adaptive behaviour than a 300B parameter NLP model trained on the entire internet. They propose a framework and a challenge to measure adaptive behaviour: the embodied Turing test. In their words:
An expanded “embodied Turing test” would benchmark and compare the interactions with the world of artificial systems versus humans and other animals. […] An artificial beaver might be tested on its ability to build a dam, and an artificial squirrel on its ability to jump through trees. Nonetheless, many core sensorimotor capabilities are shared by almost all animals.
The way they propose doing this is by building up a series of incremental challenges, starting from simple behaviours (e.g. locomotion) and organisms (e.g. nematodes) and building up on those systems one by one by a process of phylogenetic refinement. The paper that embodies the clearest this vision this year is this wacky NeurIPS paper from Tony Zador, Bhattasali and Engel where they show how to build an RL agent that can swim by reverse engineering the nematode (C. Elegans) swimming circuit.
Yes, and…
I am enthusiastic about each of these research programmes. I think they’ll be reinforced by an additional focus on applications of differentiable brain models to brain health (top right corner). With a perfect digital twin of a brain, one could figure out how to stimulate the brain in the right way to give relief to people with neurological disorders. This corner of the neuroAI diagram has deep intellectual roots in cybernetics, but it’s broadly underexplored. Developing the tools to study the brain’s reaction to causal manipulations might give modellers precisely the data they need to make progress in other corners of neuroAI. I wrote a long read about this idea here.
Skeptical outlooks
Not everybody came out as pro-neuroAI this year: we saw a lot of skeptical takes and monster Twitter threads. Is neuroAI broken? Let’s find out.
High-performing neural network models of visual cortex benefit from high latent dimensionality
This paper from Elmoznino and Bonner (2022) looked at the dimensionality of convolutional neural networks acting on images. Here, they defined dimensionality as the effective number of non-zero dimensions via the singular values of the encoding matrices across the ImageNet validation set. They found that networks with high dimensionality correspond better with area IT of the visual cortex. Super interesting idea and pretty convincing.

This paper was interpreted by some skeptics to mean that it’s not really the network that matters; it’s the fact that the network projects to some high-dimensional space. In other words, one could construct a network that projects input to random directions in a high-dimensional space and that would match well with the brain. That would be a blow to the interpretation that IT is similar to a high-level layer of a deep convolutional neural net
However, that’s not what the paper found: instead, they found that in their sample of neural nets, the ones with higher dimensionality had compact class manifolds. That means that images with the same label were close in feature space. That would not be true for random projections. This paper adds to the body of evidence that there’s something special about the way the brain iteratively refolds image manifolds into beautiful origami swans useful representations; see also Arna Ghosh’s paper for an application of this idea to DNN regularization.
There’s still a possibility that it’s easier to match a low-d brain to a high-d network because of a needle-in-a-haystack effect; there’s just more potential matches within a high-d representation. I think we’ll need more subtle metrics than R2 from linear regression to see that. Elizabeth Dupre has a beautiful presentation at MAIN2022 on the myriad bespoke metrics fMRI people use that we should probably import for neurophysiology.
Brain hierarchy score: Which deep neural networks are hierarchically brain-like?
This paper from Nonaka et al. is from 2021, but I heard about it in 2022 so it makes it into this review. They measured the match between a unit in a given layer of a CNN and the best matching visual cortex voxel and vice-versa to create brain hierarchy scores: how close is the match between V1-V2-V4-IT of the visual cortex and layers 1-2-3-4 of the CNN? This is a harder criterion than to ask that on average the layers of the CNN match those of the visual cortex. They found that shallower models with fully connected layers performed best. Furthermore, even the best DNNs only recapitulated the hierarchy of the brain coarsely.
This does highlight a failure mode of the correspondence between DNNs and brain: DNNs trained end-to-end are underspecified in their correspondence between a specific brain area and an intermediate layer. To resolve this, I think we’ll need to directly supervise intermediate DNN layers by sprinkling in brain data to constrain specific layers to match specific areas. St-Yves et al. (2022) found that you can train a big DNN with multiple readout heads to account for responses in V1, V2, V3, V4h. This doesn’t do better than training separate networks according to traditional criteria like R2 or RSA, but it does better respect the hierarchical structure of the visual cortex.
Reassessing hierarchical correspondences between brain and deep networks through direct interface
Sexton & Love (2022) propose a stricter evaluation of the correspondence between brains and deep neural networks, what you might call the old switcheroo: if the brain really is a proxy for a neural network (or vice versa), then it should be possible to replace the input to an intermediate layer of a neural network with a brain-based prediction of that input. They did this and it didn’t work very well unless the target was one of the very last few layers of the neural network. They conclude from this that the hierarchical correspondence between ANNs and brains must have been incorrectly evaluated in the past, since all brain areas – including primary visual cortex – best correspond to higher-level layers of ANNs.
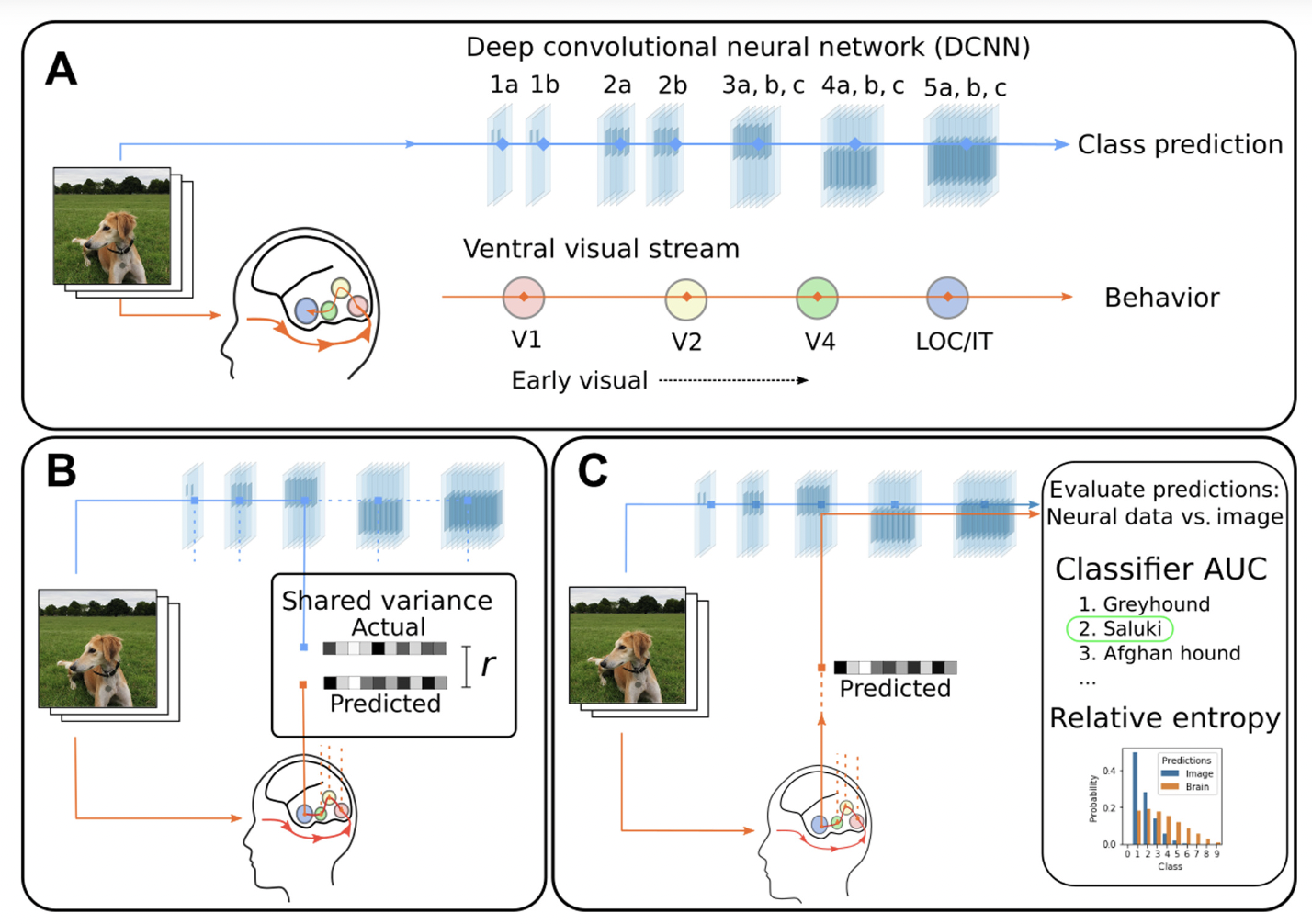
On the surface, this paper makes the same point as the brain hierarchy score paper. I liked the brain hierarchy score paper, but I’m skeptical about this one. My criticism is pretty simple: you can’t just plug a brain into an ANN and expect it to work out of the box. The ANN is not trained to deal with the noise inherent in brain data, the linear regression doesn’t take into account that noise (error-in-variables model), nor does it attempt to mimic the spatial structure of the mismatch (assumption of iid noise in multiple linear regression). A quick sanity check would have been to learn the weights by minimizing the multinomial classification loss on ImageNet rather than using a sum-of-squares loss for the intermediate activations. I bet it would reverse the conclusions in Figure 2. That being said, the paper is based on open data, so I think it would be a feasible and enlightening project for an enterprising student to come up with a method that could solve the brain-DNN impedance mismatch.
Edit: the senior author Bradley Love let me know in the comments that they did run this sanity check. The plot thickens! I’d still like to see normative simulations to verify that, for example, if you plug a CNN with one seed into another CNN with the same architecture and training but a different random seed. I think the CKA work from Kornblith et al. (2019), as well as follow-up work with Alex Williams give a really nice template for how to validate new metrics comparing brains and neural networks.
But wait, there’s more!
After I first published this, a few people pointed out in the comments and on Twitter other papers with a skeptical outlook. Whatever doesn’t kill neuroAI will only make it stronger (cf. Doerig et al. 2022), so here they are:
- Deep Problems with Neural Network Models of Human Vision: there’s a long history of human psychophysics and vision psychology. A lot of that has been brushed aside in neuroAI with a narrow focus on accounting for R2. This paper makes the point that we need more subtle metrics, which is always a winning argument in my book. In particular, we should be able to replicate subtle effects measured with parametric laboratory stimuli through classical psychophysics. I’m on board with this idea. Where I have a difference of opinions is in the proposed alternative: non-image-computable, bespoke computational models. I can’t do encoding, decoding, optimization or control with this set of models, so I don’t think they’re viable candidates for best-in-class models of visual processing. Perhaps hybrid models will come along.
- Successes and critical failures of neural networks in capturing human-like speech recognition. A similar paper to the previous one, sharing some authors, but this time focused on audition. I haven’t dug deeply into this one yet.
- No Free Lunch from Deep Learning in Neuroscience: A Case Study through Models of the Entorhinal-Hippocampal Circuit: This paper makes the point that some neuroAI papers have to bake in a lot of assumptions, fine-tuning research degrees of freedom until they get the desired result. They show this for models of grid cell formation. I like this paper a lot: it shows a particular trap in modelling that we should avoid. One way to show that our modelling choices are sensible and robust: doing sensitivity analyses (inspired by Bayesian modelling).
Auditory cortex and language
We saw a slew of papers that link auditory and language processing areas to deep neural nets. Some rapid-fire highlights:
- Self-supervised audio models match auditory cortex: Vaidya et al. (2022) found that self-supervised auditory models (SSL-audio), especially HuBERT, are a match to auditory cortex during story listening. They saw a recapitulation of the auditory hierarchy, with lower levels of HuBERT matching lower auditory areas and higher layers matching more conventionally semantic areas. This is consistent with a similar study from Millet et al. (2022).
- Self-supervised large language models match language processing areas: A number of studies found that transformers trained for masked language modelling or next token predictions (e.g. GPT-2) were aligned with responses of the brain to natural language. This includes Schrimpf et al. (2021), which came out late last year, as well as Caucheteux & King (2022) and Heilbron et al. (2022). Hosseini et al. (2022) found that this was true even with developmentally realistic amounts of training data: does it mean that children are little GPT-2 language prediction machines? It’s certainly an intriguing idea.
- Decoding speech from brain data: Last year, Eddie Chang and his group made a big splash demonstrating that a locked-in person could communicate by decoding signals in their intact speech motor cortex (disclosure: my old group at Facebook funded this work). They used an invasive ECoG array to record from this patient’s brain. This year, multiple groups have attempted to reconstruct perceived or attempted speech non- or minimally-invasively, which is hugely ambitious: Tang et al. (2022) from fMRI recordings, Defossez et al. (2022) from MEG, and Kohler et al. (2022) from depth electrodes. Silent speech is surprisingly amenable to decoding because it has wide brain coverage (it seems the whole brain does semantic encoding), it’s relatively low bandwidth, and doesn’t have extremely high accuracy requirements to be useful. Perhaps in a not-too-distant future I can silently speak to my device
Digital twins, BCIs, stimulation
I mentioned earlier that differentiable brain models (i.e. digital twins) could be used to predict the effect of stimulation on the brain and tune that stimulation through gradient descent (top right corner of the neuroAI diagram). I saw two papers that really ran with this idea this year:
- Differentiable models of retinal implants: Granley et al. (2022) showed that one could tune the stimulation pattern of a retinal implant to best stimulate the retina using a differentiable model of the effect of the stimulation. They showed in simulation this could give clearer phosphenes that are closer to the ideal of a dot-matrix display. This was one of my favorite papers of the year: obviously important idea, subtle modelling, great proof-of-concept.
- Differentiable, personalized models of cochlear implants: Drakopoulos and Verhulst (2022) take this idea one conceptual step forward by demonstrating that one could tune a cochlear implant to one’s particular dysfunction, using a differentiable model of the cochlea.
This idea of optimizing stimuli using a proxy model also has applications for fundamental research: Gu et al. (2022) demonstrate making maximally activating stimuli (i.e. localizers) for particular brain areas measured through fMRI, while Cobos et al. (2022) build image metamers of the visual system of mice that transfer across individuals.
Non-convolutional and quasi-convolutional architectures for vision
I wrote last year about an apparent mismatch between convolutional neural nets (CNNs) and the visual cortex: brains don’t have a mechanism for weight sharing that we know of. This year, a number of papers came out investigating this and proposing solutions:
- Convolutional structure emerges in fully connected networks: Ingrosso and Goldt (2022) show that localized filters with convolutional structure can emerge in fully connected networks trained to solve a task on inputs with non-Gaussian statistics. They then develop a theory for when this these localized filters may emerge. I’d like to see this type of work expanded beyond toy problems and with known cortical architectural biases baked in, namely sparse, locally connections.
- IT domains emerge in topographic layers: Blauch, Berhmann & Plaut (2022) propose a non-convolutional model for the emergence of domains in IT. Basically, they use a standard convolutional base for V1-V2-V4, and allow the V4-IT connection to be fully connected. IT is instead modelled as a topographic layer with local connections instead of a convolutional layer. They show this arrangement can learn domains specialized to domains, faces or scenes.
- Visual streams emerge in topographic networks: Finzi et al. (2022) take a similar approach, this time learning a self-supervised representation of images with a topographic layer on top of a ResNet-18 backbone. They show that this can account for the segregation of different visual streams in visual cortex. This is broadly consistent with our 2021 NeurIPS paper.
- Topographic maps through kernel averaging: Bashivan et al. (2022) build a new type of topographic layer by averaging over the kernel dimension. They find filters which slowly vary spatially, not unlike the pinwheels and orientation domains of primary visual cortex.
- Pooling strategies in V1 can account for the functional and structural diversity across species: after I originally published this blog post, the author let me know about this cool study published in PLoS Comb Bio with a similar idea as Bashivan et al. to explain maps and selectivity in V1 of different species. As I said many years ago, topography conquers all.

Food for thought
Finally, here are some papers that either made me smile or made my blood boil, but definitely didn’t leave me indifferent:

- MouseNet: fantastic idea: create a CNN that mirrors the architecture of the mouse visual cortex. Lots of technical detail in there about circuits and connection patterns. Did they find this network to be a better match to mouse visual cortex? No! In fact, they found that a plain VGG was a better match to the areas they were looking at. Big caveat, however: they used ImageNet as the task to train the network. Points towards the need to train neural nets with more ecologically relevant tasks or with direct supervision for intermediate areas.
- Astrocytes and neurons implement transformer architecture: this is a sort of left field proposal for how neurons and astrocytes might implement self-attention. The idea is that an astrocyte can implement a shared multiplier across multiple synapses. The astrocyte here is viewed as a computational element that uses calcium to maintain state. There’s definitely a few fishy things in this paper, like the softmax implemented through random cosine projections (how would a neuron implement a cosine function?). More generally, I can’t make up my mind about whether this is truly biologically plausible or not, because I don’t know anything about astrocytes, but I think it’s very ambitious and interesting.
- Sentient neurons in a dish learn how to play Pong: boy I didn’t like this paper. Published in a prestige journal that shall not be named, this paper demonstrated a hybrid computational architecture where a set of biological neurons in a dish solved a Pong. This is a very cool idea, a follow-up to Steve Potter’s work on animats. There’s a genuinely new method proposed to interface biological neurons and virtual environments so the neurons actually learn something based on the free energy principle. However: this paper was super hype-y (”the hybrid NN achieved sentence”, come on), the results were barely above chance, and the core idea, that the HNN would arrange itself so as to make the environment more predictable, untested. Someone (not me!) took the Twitter threads and put it on PubPeer, if you want to see other people’s takes.
- Brain Dall-E: two of the biggest stories this year in AI were diffusion models (Dall-E 2, Stable Diffusion, MidJourney and the rest) and ChatGPT. It was only a matter of time before someone would take one of these and mix them with brain data. This paper uses a Latent Diffusion Model (Rombach et al. 2022), an open source model distinct from, but in the same model family as the closed source Dall-E. They use this to decode brain data while people were viewing images in the scanner. Basically, a text-conditional diffusion model normally works by taking a sentence, encoding it into a fixed length vector, then using that conditioning information to bias a denoiser (for instance by changing the scaling of normalization layers). It’s possible to learn a model which uses brain data to create desired fixed length conditioning vector instead, hence Brain + Latent Diffusion. This works remarkably well. I would like to use this while sleeping so I can finally remember my dreams. After I published this, a reader let me know of a similar paper from Takagi and Nishimoto which uses Stable Diffusion checkpoints; the difference between the LDM used in the first paper and this one, AFAICT, is that the first LDM is trained on ImageNet, whereas this one is trained on LAION.
- Predictive coding: there were a couple of papers on predictive coding, but none more elegant than this one from Tim Kietzmann’s group which came out late last year. They show that predictive coding can emerge by minimizing the total energy needs of a network. They use a new form of regularization that takes into account the cost of EPSPs. I thought this was very elegant and I’d love to see it expanded to more realistic scenarios involving naturalistic movies.
- Letter perception as neuronal recycling: if there’s one big mystery in visual perception, it’s how do we read? Clearly we haven’t had the time to evolve brain processes specific to reading, because writing is such a recent invention, so we must in some sense recycle existing hardware to do so. This excellent paper from Talia Konkle’s group tests this hypothesis. They train different neural nets on either generic object recognition (i.e. ImageNet) or specifically letter recognition. They find that generic networks are a better match than specifically letter-trained networks. Then they ask whether they can get an even better fit by fine-tuning an object-recognition network for letter perception, and they find this is indeed the case. This is a great strength of neuroAI approaches: we don’t have time machines to study human evolution, we can’t do causal experiments on natural selection, but we can study the evolution of brain processes in silico.

Onwards to 2023
Look back: Read the 2021 year end review.
So what to make of all this? In terms of insider baseball: If there’s one lesson I saw this year repeated over and over again, it’s that architectural choices alone have an overall relatively small influence on how well an ANN is matched to a brain. Brain-Score is getting pretty hard to beat. I think we will see a paper (or papers) that 0) use an architecture that is brain-like, 1) carefully select datasets to match ecologically relevant and 2) use auxiliary brain data to enforce that one brain area = one DNN layer to make a big dent in Brain-Score.
I’m seeing tantalizing hints that people are really starting to think about applications. I also see that neuroAI is becoming bigger than any particular lab, with multi-lab research programmes being put forward. We may see a BRAIN initiative-level effort across multiple labs come to fore. It’s a great time to jump into the fray!

10 responses to “2022 in review: neuroAI comes of age”
[…] in depth. We’ve seen some of the same authors extend this work to stochastic representations. Furthermore, empiricists have pointed out problems that current metrics don’t capture, for example, hierarchical correspondence. I think it’s an exciting time to think deeply about […]
[…] natural-looking samples. Two recent papers (Chen et al. 2022, Takagi & Nishimoto 2022), which I reported on in the last post, demonstrate these ideas. They mapped fMRI data to the latents of a latent diffusion model to […]
Thanks for looking at our paper (https://www.science.org/doi/10.1126/sciadv.abm2219) One quick correction on your comment: “A quick sanity check would have been to learn the weights by minimizing the multinomial classification loss on ImageNet rather than using a sum-of-squares loss for the intermediate activations. I bet it would reverse the conclusions in Figure 2.” We actually did what you suggest already and report the results in the Supplementary Figure S4. Same pattern! :-) We did a lot of other checks on our results as well, some reported, some not. It’s real :-)
If you don’t mind: personnaly instead of using sentence embedding (that IRC can greatly suffer from out of vocabulary issues) I would resort instead to using scikit-learn’s TF-IDF vectorizer, with hugging face’s BERT as tokenizer and nltk’s english stopwords list.
The problem wasn’t the sentence embedding, it was that there wasn’t enough data points to make a satisfying looking point cloud
If you happen to put the “dataset” somewhere on the internet I’d happily give it a try as I’m very interested in this kind of visualization! Have a nice day.
Thanks for sharing this exciting review of developments in neuroAI in 2022. Is it alright to share our work here? We started using RNNs to model event-related potentials, publishing four related articles:
https://doi.org/10.1111/ejn.15736
https://iopscience.iop.org/article/10.1088/1741-2552/ac9257/meta
https://doi.org/10.1016/j.neuroscience.2022.10.004
https://doi.org/10.3390/s22239243
2023 is sure to be filled with more exciting developments – and hopefully some of them will turn out to be useful!
Regarding the claim that DNNs are providing a good account of human language, Chomsky in this “AGI debate” notes that a profound problem with current models is that they can not only learn possible languages but also impossible ones. https://www.youtube.com/watch?v=JGiLz_Jx9uI
This is the paper he is referring to I think:
Jeff Mitchell & Jeffrey S. Bowers (2020). Priorless Recurrent Networks Learn Curiously. In the Proceedings of the 28th International Conference on Computational Linguistics. http://dx.doi.org/10.18653/v1/2020.coling-main.451
And from 2022 there is this:
Federico Adolfi, Jeffrey S. Bowers, David Poeppel (2022). Successes and critical failures of neural networks in capturing human-like speech recognition (preprint) https://doi.org/10.48550/arXiv.2204.03740
I think there is a serious problem that proponents of NeurAI are not engaging with the serious challenges that have been put forward. But again, happy to be challenged on this!
You missed a few relevant papers in your Skeptical outlooks section. From my lab you might consider the follow article:
Jeffrey S. Bowers, Gaurav Malhotra, Marin Dujmović, Milton Llera Montero, Christian Tsvetkov, Biscione, Guillermo Puebla, Federico Adolfi, John E. Hummel, Rachel F. Heaton, Benjamin D. Evans, Jeffrey Mitchell, Ryan Blything (2022). Deep Problems with Neural Network Models of Human Vision. https://doi.org/10.31234/osf.io/5zf4s (Now in press in Behavioral and Brain Sciences).
Would be interested in your take on our arguments. Jeff
I did read it, yes. It makes a lot of the same arguments as Serre (2019) or Lindsay (2020) about how CNNs differ from the visual cortex (section 4.1 in particular). I think it’s useful to have an explicit list of mismatches between brain and ANNs so we can advance ANN methods. I agree with the argument that a change in R2 of 0.01 on brain score doesn’t really tell why a model misfits and that more parametric stimuli are helpful for this. This argument predates ANNs as models of the brain, and is equally applicable to shallow models of visual cortex, see for instance in Mineault et al. (2011) we mixed reverse correlation and parametric stimuli to figure out “what’s wrong” with a particular model of area MST, so we could fix it. There’s no reason why this couldn’t be integrated in brain-score, and I think the community is moving towards more multidimensional evaluations. I think most arguments against CNNs as models of visual cortex are very much “belt-attacking” arguments in the nomenclature of Doerig et al. (2022).
Where I have some serious qualms is about the alternatives you mention. For my purposes, I need differentiable, image-computable models of brain functions to use them as control-theoretic proxies. Grossberg-style models that are not image computable are simply not viable for this purpose (disclaimer: Grossberg is my academic grandadvisor and my PhD advisor very much emphasized to me the limitations of this style of model so I might just be parroting his own scepticism). From an aesthetic perspective, I also dislike this style of model which require a lot of hand tuning to replicate tiny amounts of data (insert a quip about Von Neumann’s elephant). The data coming out from the neuroAI literature is that the architecture (very much Grossberg’s emphasis) doesn’t matter nearly as much as the dataset and the optimization procedure.