

It takes dedication to keep up with the scientific literature. 2344 papers were accepted at last year’s NeurIPS conference. Who has time to read all of that? It’s difficult to see the forest from the trees as ever more research is published.
What if every single one of us had infinite access to world experts in any field of field of study?They could recommend papers to read, based on:
- relevance
- accuracy
- importance & novelty
In this essay, I’ll try to convince you that we’re not far off from that world. Advances in natural language processing (NLP) and large language models (LLMs) mean that it’s becoming possible for machines to understand natural language, including the prose in scientific papers. We have only started to see these advances deployed, but my bet is that it will change how we consume and create science over the next few years. Let me recap the progress in NLP over the last 5 years and paint a vision of scientific natural language processing in the near future.
Subscribe to xcorr and be the first to know when there’s a new post
NLP works and it’s commoditized
I last looked seriously at NLP 5 years ago, and back then, it didn’t really work except for narrow use cases. Seeing recent results from PaLM and DALL-E 2 motivated me to pick a book on NLP and apply it to a semantic search project. In that 5 years, the field has completely changed. Let’s recap.

TL;DR: NLP now works. It’s also heavily commoditized. Anybody with a technical skillset–and increasingly non-technical people–can train a model to solve any number of NLP tasks. Some of the biggest changes are that:
- We have Transformers, a neural net architecture that scales well and can deal with large temporal contexts. The models vary from encoder-only, like the famous BERT model, decoder-only, like GPT-3, and encoder-decoder models like ones used for translation.
- We have powerful pre-training tasks, especially masked language modelling, to pre-train large scale models that are useful for a number of tasks.
- Models have been scaled tremendously and now routinely number in the 100 billion parameter range, and increasingly are trained on a significant subset of all the text on the internet.
- The fundamental paradigm for adapting to specific tasks has changed. We now routinely use pretrained models either as is, with in-context learning, or we refine pre-trained models. This is far cheaper, less burdensome, and scales better than training a model from scratch.
With these advancements in NLP models and training paradigms, the tooling has become far better:
- HuggingFace is essentially building Github for transformer models; anybody can download one of over 10,000 pretrained models, and either use them as is or fine-tune them on their own data.
- Access to datasets is far easier as well, again through HuggingFace.
- Access to hardware is commoditized. Anybody can rent a supercomputer with 320 GB of GPU RAM for 30$ an hour.
- If one doesn’t want to bother with training and deploying models by themselves, they can use APIs which abstract away all the messiness, including OpenAI’s GPT or cohere.
What do I mean when I say that the models now work? There are a number of tasks which we now know how to handle, provided that we have a sufficient amount of data:
- classification of single sentence, for instance to evaluate emotional tone or valence
- named entity recognition, e.g. extracting the names of compounds, companies and people from text
- extractive question answering, figuring out which passage in a document is relevant to answering a question. For example, extracting the name of the first prime minister of a country from its Wikipedia article
- document embedding and semantic search, e.g. finding other relevant documents from a seed document
- summarization, i.e. generating a short summary of a paragraph or document
- translation, e.g. from English to French or Python to C++
- autocomplete, including autocompleting code
- text generation, including steered text generation, e.g. generate convincing ad copy for a product from a list of features
That’s a long laundry list, but what is the relevance to how we do science?
Scientific NLP can ease information overload
Let’s go back to our initial thought experiment, having access to a world expert advisor to help us navigate the scientific literature. Because NLP now works and it’s highly commoditized, we’re starting to see scientific natural language processing being scaled up into real products.
Determining relevance
If you have a list of papers you have written, or a list of papers which you’ve identified as relevant to something you’re interested in, it’s becoming straightforward to find other relevant papers in that vein. Relevance can be determined from a number of signals, in particular semantic similarity as well as citation graph.
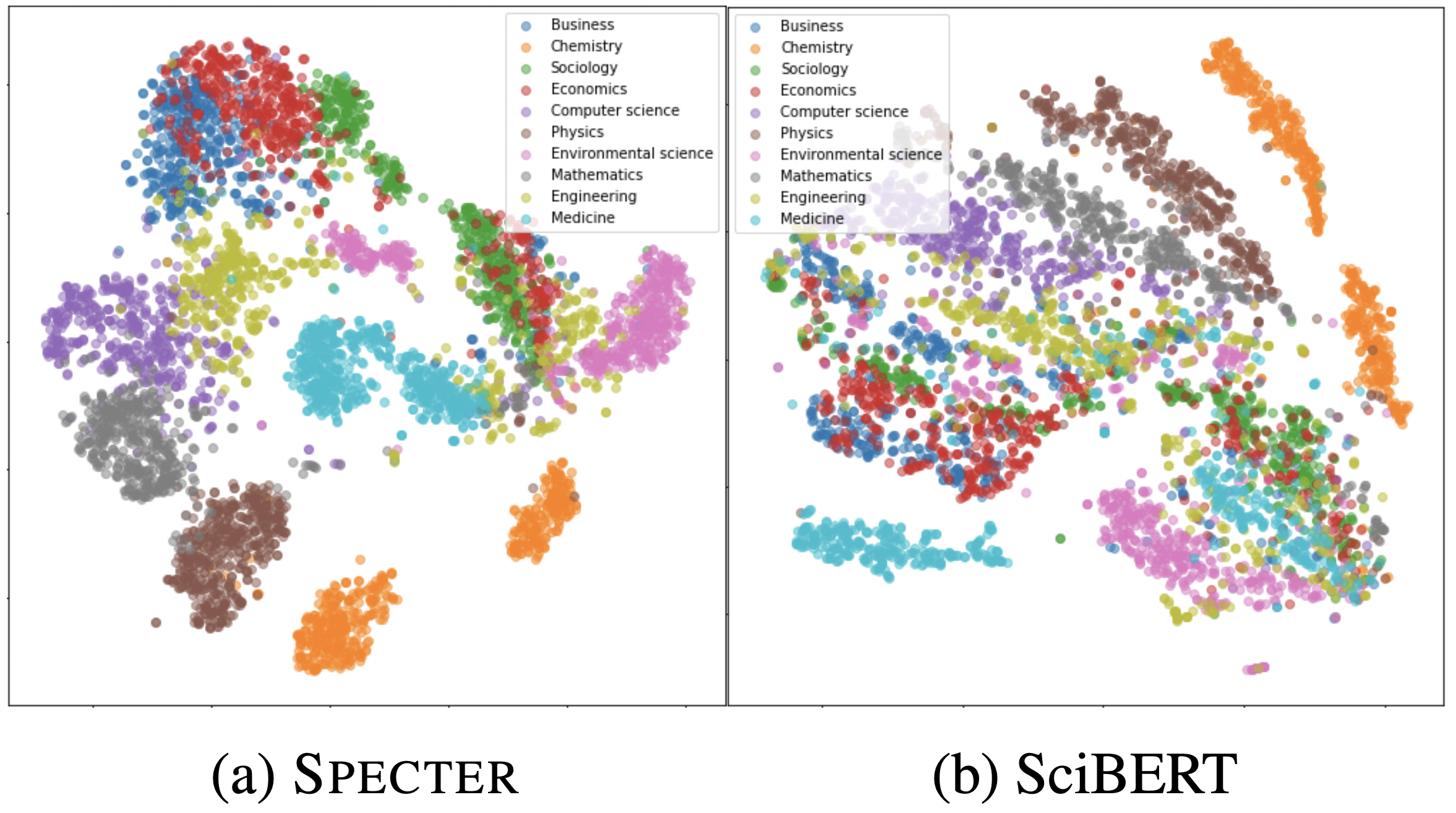
A prototypical work in this space is SPECTER, a system from the Allen AI institute to find semantically related papers. A BERT-like model is pretrained on a masked language modeling task on unlabeled scientific texts (SciBERT): words are blanked out at random and the transformer is trained to find the missing word. This gives rise to one vector per token, in this case a 768-dimensional one. The tokens are then summarized, in this case extracting the vector of the special first token, although you could also take the average of tokens over a document.

The pre-trained network is then fine-tuned on a set of papers with a triplet loss: it moves similar papers together and dissimilar papers away from each other. Citations are used as a proxy signal for similarity: make papers which cite each other close to each other, and papers that don’t cite each other farther away. The result is a model that can generate fixed-length dense semantic vectors from each document. This can be used to retrieve similar documents, by finding other documents which are close together in this high-dimensional vector space.
Don’t Google Scholar, Mendeley, etc. already do recommendations? Yes, of course. However, consider these other uses of NLP in this context:
- You can use a question as the seed document. That means you can ask a question in natural language and obtain a ranking of relevant documents that answer this question. That means you can do a search in a field that’s completely unknown to you and obtain good starting documents.
- The search engine can summarize a document for you. At a glance, you can figure out what a recommended document is about and select it for further reading. An example of such a system is AllenAI’s TLDR, an extreme summarization method. You can see this in action on elicit.org and on Semantic Scholar.
- You can get the language model to tell you why it chose a given document. For instance, you can ask GPT-3 to tell you why document A is relevant to document B, and oftentimes the answers are quite reasonable. When I asked GPT-3 to explain why someone interested in a famous paper comparing deep nets to brains would be interested in another paper on it, it answered quite reasonably that “they are both about the ventral visual stream and object recognition”. It’s not very precise but it’s tantalizingly close to “getting it”, and the gap will most likely continue to decrease in the future.

Recommendation systems can also be used to find new collaborators, matching students and postdocs to PIs, and students about to graduate to industry jobs. That means less friction in science and more opportunities for all.
Determining accuracy
It’s easy to grasp the value of semantic search: “what if we had Google for science, but better?”. However, this only scratches the surface of NLP’s potential uses for science. Consider determining the accuracy of a paper. There are many features of documents relating to trust and accuracy that are tedious for a human reader or reviewer to go through. These include:
- Is prior literature represented fairly and citations correct? Especially in the intro, the prior art can presented in non-exhaustive, biased ways, over-citing one’s own prior work, misrepresenting consensus or lack thereof, etc. Furthermore, authors may cite bad papers as evidence: citing underpowered, flashy or controversial papers without introducing proper caveats. Assuming we had a good semantic search engine (previous section) and a pre-existing trust system (this section), this could be automated.
- Are the methods complete? If I took a result from a paper, and I wanted to recreate it, is it mentioned how that result was generated? Extractive Q&A can help find relevant passages in the methods.
- Are the methods appropriate? There are already crawlers for papers that alert authors to statistical issues. This is a logical continuation of such efforts. Is the study prospective? Retrospective? Was a power analysis run? Are there enough subjects? Are the methods similar to those of other papers in that field? Are those papers trustworthy?
- Are the claims substantiated? Entailment is an NLP task where one compares two statements and verifies that one follows another. One can build a whole statement tree and see whether the argument holds together. The more holes in the argument, the less trustworthy the papers.
- Is the abstract representative of what’s in the paper? So many times you see papers where the abstract sounds awesome but the paper doesn’t substantiate its claims. With the claim tree resolved we can verify the representativeness of the abstract.
- Is the paper plagiarized?
- Is the paper written by authors who tend to write bad papers?
Now imagine having a trustworthiness score for each paper, with attribution for which passages are dubious and which are trustworthy. This would be immensely helpful for reviewers and readers, and perhaps a good learning tool for students so they can understand how to strengthen their papers.
Importance and novelty
We have tools for determining importance and novelty:
- Prestige journals.
- Affiliation.
- Social media.
I think everyone is starting to understand why prestige journals are a bad idea: prestige journals take money from taxpayers and put them into the pocket of shareholders that neither do research nor do much to advance science. In fact, they actively create barriers to science by placing it behind paywall. They have odious profit margins and extract free labor out of an exploited population (scientists). They delay publication by months, the judgement is extremely noisy, and those papers which do end up being published are more likely to be wrong than those in a less prestigious journal.
Affiliation is much the same way. Sure, if you see a paper from a Harvard researcher or a Nobel prize winner you’re more likely to read it. But affiliation, like prestige publication, suffers from the safe defects: it distorts the marketplace of ideas and leaves very good science from non-Ivy-League schools unread.
Social media is a bottom-up way of measuring importance and novelty of new work, and indeed, altmetric has built a business around measuring this buzz. There is signal there. However, having a very critical part of science diffusion in the hands of private corporations whose core mission is not science is risky in the long-term. Science Twitter could get disrupted by global algorithmic changes on the platform. For example, a higher focus on comments as a metric – algorithmic engagement – might surface less papers and more recurring debates in your feed; less signal, more noise. The reality is that science Twitter is just a very small, poorly monetizable, insignificant part of Twitter as a whole, and its continued healthy existence could very much change.
None of the existing methods fully satisfy the core needs of the scientist as consumer: to see new developments in areas close to their area of research in realtime. Neither do they satisfy the needs of the scientist as producer: to have a fair chance of their science being read and fairly evaluated for what it is.
How can NLP help? There is some work attempting to predict future citations based off of different factors, a potential measure of importance and novelty. Some factors like the shape of the citation graph (e.g. citing papers from two different, disconnected areas of science) can be predictive of novelty. Perhaps it will take a truly deep understanding of the scientific literature to gauge that a new paper is revolutionary, but in the next 2-5 years I can easily see more modest goals being achieved:
- sift through the literature to give you papers that are relevant to you, giving you short summaries of these documents
- warn you if a new paper is likely unreliable because of its methods
- free up time so you can deep dive into relevant papers with potential, and decide for yourself whether it is important
A platform that facilitates goals 1 and 2 could be an ideal location to start a science-focused social medium. The captured data could be used to build models to predict importance over the long term.
The road ahead
The vision I outlined here is fairly short-term. A great resource to get an idea of the next 5 years of science and NLP is the published roadmap from elicit.org’s parent org, ought.org. Another source of inspiration is the abstracts submitted to the scinlp conference. These are glimpses of the near future.

Medium-term, I expect that the switch will flip, and that scientific research will be consumed more by computers than humans. Meta-analyses and review papers are already based on distilling existing data, and we can foresee that computers will be far more agile in creating texts that require distilling hundreds, if not thousands of source documents. There will eventually come a time where LLMs or their successors will be able to generate new scientific discoveries through distillation. It might not happen just right now, but certainly science will look far different in 10 years for this reason.
I also expect that large language models, embodied as assistants, will be excellent tutors. If a computer understood your learning path, they could become the perfect tutor, feeding you just the thing you need to learn at the time you need it. Both humans and machines will be far more capable as a consequence. It’s up to us to make sure this future is also fair and accessible to all.
Further resources
NLP software and APIs
Semantic scientific search engines
Organizations building free SciNLP models
Books
Footnote
The social media copy for this blog post was generated by GPT-3, and lightly edited by me. The prompt was “Write a compelling short teaser of this blog post for social media (288 characters max)”


3 responses to “Large language models will change science”
Thank you for your brilliant text. Indeed, it is impossible to keep up with relevant literature in my field nowadays, and finding tools to get important information any time I start a project or discuss results is a must. Anyway, the discussion of what is really a good descriptor of “relevant” literature is of much interest.
[…] a space of possibilities and then trying several. Visualizing data to find patterns. Finding and digesting relevant literature. Training new students so they can do the same. Furthermore, as mentioned, in certain more abstruse […]
[…] Patrick Mineault, 30 May 2022, Xcorr […]