
This blog post was adapted into an article for a16z’s Future.
It’s been 60 years since Hubel and Wiesel first started unlocking the mysteries of the visual system. Proceeding one neuron at a time, they discovered the fundamental building blocks of vision, the simple and complex cells. Yet for a long time, neurons in high-level visual cortex were something of a mystery. What kinds of neural computations support complex, flexible behaviour?
When I defended my thesis in 2014, I confidently stated that we did not know how to build computers that could see like humans do. Yet only a few months later, Niko Kriegeskorte and Jim DiCarlo’s labs showed that deep neural networks (DNNs) trained on ImageNet represent visual information similarly to shape-selective regions of the visual brain. Follow-up research, including some of my own, increased the number of visual areas that could be explained this way, while also decreasing the numerical gap between brains and computers.
There are some remaining qualitative gaps, covered in Grace Lindsay’s review: DNNs are more susceptible to adversarial stimuli than humans; they require far more training data than brains; they’re biologically implausible in that they don’t follow Dale’s law; etc. As I argued in my previous post, people are working on all these fronts. We will be able to build a comprehensive in silico version of the visual brain over the next decade. What next?
In this essay, I’ll argue that we should build, over the next decade, an in silico version of the visual brain that will unlock a whole array of applications in human health. We’ll be able to exercise fine control over our visual experiences, and this will enable therapies delivered through the visual sense. Some therapies will be applicable for people with neurological disorders, while others will enhance healthy people. It will be unlocked by stages of technological development: first with the maturation of neuroAI, then through consumer augmented reality (AR), and finally (and much further down the line) with brain-computer interfaces (BCI) through closed-loop control. Follow me as I take you on a tour of the near future of visual neuroAI.
This is one of my longer posts, and it covers a lot of ground:
- What’s neuroAI, and why do I think that neuroAI models will keep getting better, fast?
- Why building models of the visual brain is more than just a satisfying intellectual exercise, it can actually help people
- How does visual communication and control currently work, and how will they change when visual neuroAI will be deployed?
- What are the technological trends that will unlock these neuroAI applications? How AR and BCI will allow closed-loop control of the visual system
Subscribe to xcorr and be the first to know when there’s a new post
The long-term trend of neuroAI
Modelling fills different roles. David Marr classified neural computational models into 3 levels of explanation:
- High level (computational theory): What is the goal of the computation?
- Mid level (representation and algorithm): How can this computational theory be implemented?
- Low level (hardware implementation): How can the representation and algorithm be realized physically?
For some, the high-level theory is the cornerstone of their work: that’s the approach taken by David Marr and by James Gibson. Visual neuroAI takes a different approach: it finds image-computable functions that can solve a task (e.g. ImageNet classification) and aligns them to neural representations. The basic paradigm of the field has scarcely changed since the early days of neuroAI:
- train artificial neural networks in silico without the use of brain data, for example for object recognition on ImageNet
- compare the intermediate activations of trained artificial neural networks to real brain recordings, e..g using linear regression, representational similarity analysis, centered kernel alignment, etc.
- pick the best performing model as the current best model of the visual brain
- (optional) open the black box of the best model to determine how it accomplishes its task and gain insight into the brain’s computations
NeuroAI solves the representation and algorithm question–how can we implement the computations that the brain does?–using an approach that is primarily empirical.

The mid-level approach is more empirically grounded than the high-level approach, which is advantageous when investigating a high-dimensional sense like vision that has gone through years of evolution. There are simply some facts about vision which will never be explained by an optimality principle: the fact that the mammalian retina is wired up the wrong way around, for example. Despite their empiricism, mid-level models can help us understand high-level goals: we can perform infinite experiments and rapidly iterate in silico.
Mid-level models differ from lower-level approaches, like those pioneered by MiCRONS and the Blue Brain project that seek to measure and model every synapse. While low-level models offer exquisite detail of small brain areas, mid-level models offer better coverage. They implicitly use a coarse-to-fine refinement strategy, with early versions of models accounting for a lot of the low-hanging variance, and later versions iteratively refining those models.

The data flywheel
One of the biggest reasons that mid-level approaches have the wind in their sails is that they’re susceptible to the data flywheel effect. A data flywheel is a concept in industrial applications of machine learning that is quite intuitive. Let’s say that you have a data-driven product that’s driven by a machine learning model: for example, an app that identifies birds from their sound. You build an alpha version that is not very accurate. However, if it’s good enough that some people find it useful, you’ll get some users. They will upload more snippets of birdsong and might agree to label them on your behalf. You can use that data to build a better model. That will make the app more useful, which will bring in more users, who will collect more data on your behalf, thus making your model better, etc. Pretty rapidly you end up with the best bird identifier app in the world.
So how does the data flywheel work with mid-level models? Let’s take a look at the specific example of BrainScore. BrainScore is a community benchmarking website where anyone can submit models that explain responses in the ventral visual stream that are selective for shape and image categories. It’s similar to paperswithcode or kaggle. The candidate models must be image-computable: they make predictions about the response of a population of neurons to an image or sequence of images. The website hosts a number of datasets, a set of yardsticks against which models are evaluated. This benchmarking approach stack-ranks different candidate models, and potentially identifies what meta-parameters drive some models to perform better than others.

Benchmarking is not a perfect solution: focusing on the horse-race aspect of building models and yardsticks may not capture the intent of their designers. However, consider this: people will keep dreaming up new models, if only because of the continuing progress in computer vision. Bigger and better datasets will also be made available as brain recording tech doubles in capacity every 3.5 years. As long as we commit more models and more discriminating datasets, models at the top of BrainScore will keep getting better and better from a metrics standpoint. Moreover, BrainScore itself becomes more useful. The code that implements the the model at the top of the board is, in a sense, the best theory of computation for the ventral stream at that time.
BrainScore is specialized for the ventral visual stream, but people are doing this as well for other areas. Indeed, Shahab Bakhtiari and I presented two spotlights at NeurIPS 2021 [paper 1, paper 2] where we evaluated models of the dorsal stream, and found some standout candidates. There’s a lot of interesting, basic, curiosity-driven scientific observations regarding high-level goals of the dorsal stream that came out of this exercise. In addition, we got an engineering artifact: an in silico model of the dorsal visual stream.
Right now, our state-of-the-art models of the visual brain are the equivalent of black-and-white TV (or GANs in 2014). But with the data flywheel effect, we have a recipe to make them into 4k HDTV (or GANs in 2019). So what are we going to do with these models?
From natural to artificial intelligence and back
A dominant idea in the field is that by studying natural intelligence, we’ll learn principles by which we can create better artificial intelligence models. For example, the NAISys conference introductory statement goes:
In spite of tremendous recent advances in AI, natural intelligence is still far more adept at interacting with the real world in real-time, adapting to changes, and doing so under significant physical and energetic constraints. The goal of this meeting is to bring together researchers at the intersection of AI and neuroscience, and to identify insights from neuroscience that can help catalyze the development of next-generation artificial systems.
There are historical examples of AI drawing inspiration from natural intelligence, especially convolutional neural nets and reinforcement learning. We should continue to research divergent approaches, including brain-inspired ones, to solving problems in AI. For instance, Bayesian programming and neuro-symbolic AI are very different than “standard deep learning”, and researching these areas further could create a cache of novel ideas, should deep learning every hit a wall.
While the neuro→AI approach has been championed in both scientific papers and in popular media, we’ve heard much less about the opposite direction, AI→neuro. It’s been a bit under the radar for a little while, but I think it’s just as promising as the more familiar direction. AI is a vastly applicable toolkit that will help us understand the brain. Just in the past year, we’ve learned from AI approaches:
- how the brain can learn good shape representations in an unsupervised way
- how the brain could learn good motion representations through predicting its motor plans from its visual inputs
- how ventral and dorsal streams can emerge in parallel paths through symmetry breaking
- and how invariant visual representations can emerge through correlation across saccades.
Clearly, AI is helping us understand how vision and other sensory systems work. There are constitutive reasons why this will continue to be the case, namely that AI works on far shorter timescales than typical biology experiments, it receives a tremendous amount of funding, and it’s improving rapidly. It has the potential to open new windows into the human mind and help us understand who we are as people. But, there’s another, widely overlooked point: in silico models of the brain can be used to improve human health.
Visual communication and agency
My bet is that in silico models will give people agency over what happens in their visual brains. It will make it possible to steer visual brain activity and deliver therapies through the eyes. When we have a good model of a system, we can design policies to control it effectively: this is the subject of control theory. Visual control encompasses two concepts:
- visual communication, which is when an external agent (an artist, a marketer) attempts to control a visual system.
- visual agency, which is when we attempt to control our own visual system.
These are two sides of the same coins, differentiated by who initiates the control. Visual communication, which seeks to leave an imprint on the visual system, is already commonplace. It’s currently done empirically, however.
Consider painting:
painting, the expression of ideas and emotions, with the creation of certain aesthetic qualities, in a two-dimensional visual language. The elements of this language—its shapes, lines, colours, tones, and textures—are used in various ways to produce sensations of volume, space, movement, and light on a flat surface.
— Encyclopedia Britannica
These building blocks–shapes, lines, colours, tones, textures–are shared between painters and visual neuroscientists. Visual elements are manipulated in a purposeful way to communicate ideas and emotions. The artistic process varies, but there is almost always an element of evaluation, where the artist looks upon their work to see if it communicates the right feeling; if it doesn’t, they refine their painting. When artists suffer vision problems, because of cataracts, for example, their output changes accordingly. This indicates that the artist attempts to create a pattern of brain activity in the viewer’s brain, using their own brain as critic.


The history of painting also shows that there are ways of communicating visual information that are, in some ways, more real than real, a topic explored in Margaret Livingstone’s excellent book. Edvard Munch’s The Scream presents a purer expression of anxiety and distress than a realistic portrayal could. Although, as a painter, he could use his own visual sense to guide his craft, his work generalized across individuals to convey emotions visually. Interestingly, modern neural networks can be used to generate images aligned to emotional words; while the images are not realistic, they visually distill emotions very effectively, in a manner reminiscent of the work of painters.


So vision can change how we feel, there are a set of stimuli that are better than reality itself at eliciting certain feelings, and these stimuli generalize across people. Vision can also change how we act. Web giants have known this for some time. Google famously tested which of 50 shades of blue to use for the blue links on the search engine results page. According to The Guardian, the best choice caused improvements over the baseline of 200M$ in 2009, or roughly 1% of Google’s revenue at that time. Netflix customizes the thumbnails to the viewer to optimize its user experience. Researchers at Adobe are working on tools to predict visual attention in illustrations so people can make their materials more visually effective.
Put together, I’ve demonstrated that vision is a powerful sense; that the visual input can be easily controlled via screens; that artists and businesses are using vision to bring about desired emotions and behaviours; that in some cases, artificial stimuli can be more effective at driving these reactions than natural stimuli; but that, by and large, the ability to control one’s brain states via the visual sense is a very empirical affair. My thesis is that we’ll be ever to create ever more powerful visual media through neuroAI, AR, and BCI.
Open-loop control and applications
Nothing is in the mind that was not first in the senses except the mind itself.
— Leibniz
Let’s think about what it means to control the state of the visual brain through a model-based approach. I take the Leibnizian view that the content of the mind (”the state”) is modified by the senses to create a new state of mind. A little notation will clarify what I mean:
- The brain is initially in a state s0. By state, I mean a vector representing a concatenation of the visual brain’s activity at the appropriate spatial scale, for example at the scale of cortical columns.
- The brain experiences visual experience I(x,y,t), which consists of an image at coordinates x and y, changing over time t.
- As a consequence, the brain moves from state s0 to s1. We model this as the forward operator f: f(s0, I(x,y,t)) = s1.
- The goal of control is to find the right stimulus I(x,y,t) to bring the brain into some desired state s1.
- The controller has access to an in silico model g, where Hg = f, and H is a nuisance linear transformation.
- Optionally, the controller takes low-dimensional measurements of the final state s1 by, for example, measuring behaviour, using introspection, or tracking eye movements.
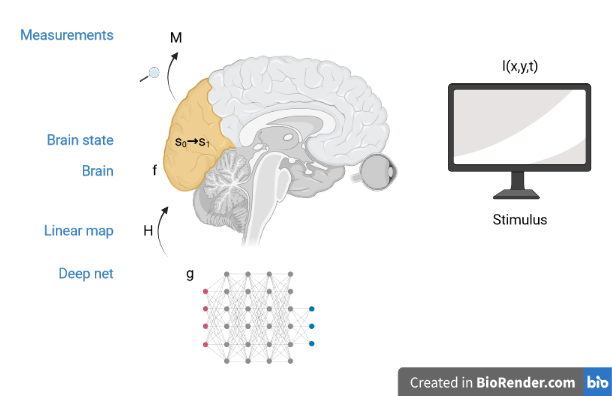
Model-free vs model-based control
Given this setup, let’s consider the two visual communication paradigms I discussed in the previous section. First, people can use their own visual systems (or a committee of visual systems) as critics. That’s the painter’s approach–I call this small N empiricism. A second method is through large-scale empirical approaches, in particular those facilitated by websites with huge amounts of traffic. You can let a million people each evaluate fifty different shades of blue to decide which one to use on Google search engine results page: you don’t need to know anything about the visual system to make that decision. This is big N empiricism. In both cases, they primarily work by a trial-and-error process of changing I(x, y, t) and measuring low-dimensional outcomes M. These approaches are thus primarily evaluative and model-free.
Model-free methods can help you evaluate which images communicate most effectively, but they can’t tell you how to generate better images. For that, you need a model-based approach. We approximate the brain’s model f via a deep neural net g. Importantly, we can backpropagate through g, which means that we can generate better stimuli to accomplish a goal, starting from a random image, using gradient descent. If our in silico model is a good model of the brain, we’ve just generated a stimulus which can bring the visual brain to a desired state.
I call this open-loop design and control. This approach is already deployed for certain applications. It’s common to use the latent middle layers representations of convolutional neural networks as critics, for instance for style transfer or to manipulate images to increase memorability. The middle layers of these networks tend to be aligned to intermediate visual representations in the brain (e.g. V4). In the case of style transfer, one starts with a photograph and modifies it through gradient descent until the summary statistics of intermediate visual representations matches that of a style image. The ineffable “looks similar” or “has the same style” is transformed into a hard metric that can be optimized to create stimuli which generate a certain brain state.
Why model-based open-loop control is promising
A disadvantage of open-loop design is that it’s sensitive to mismatch between the system and the model of the system. This can be addressed in two ways: first, neuroAI models should and can be better. I expect that in ten years:
- Models will be aligned to an exhaustive list of visual areas (ventral, dorsal, and early multimodal), such that H will be constrained by biology. Ideally, g should directly model the brain f.
- They will be biologically plausible: they will follow Dale’s law, they will have different resolution in the fovea and periphery, they will have different receptive field properties as a function of space, they will include noise, recurrence, etc.
- Models will be binocular, they will work on images and videos, they will take into account active vision (eye movements), and they may be embodied.
- They will be customizable such that scotomas, strokes, or neurological disorders can be modeled through parametric means.
- They will be steerable such that they can be adapted to mimic the visual system of specific individuals.
- They will account for temporal dynamics at millisecond (tuning), second (adaption), day (learning), and millennium (evolution) timescales .
- Eventually, once brain-reading technology becomes more advanced (see later BCI section), they will model how the brain’s internal state interacts with the external stimulus to generate successor states. Until then, they will implicitly average out the brain’s initial internal state s0 as noise.
People are already working on most of these questions in isolation. When all the elements come together in one model, open-loop control will be far more powerful.
The second way to address the prediction mismatch in neuroAI is to mix and match open-loop control and empirical evaluation (as with painters and large online services) to obtain strictly better strategies. An analogy is AI-assisted drug discovery. An AI sifts through millions of different molecules to see which ones are likely to have good binding affinity with some target. Then scientists can go to the bench and test out the top 10 candidates. It’s clear that this is a better strategy than either testing millions of different molecules directly or picking the best molecule identified by the AI and trying to commercialize that.
Application areas for open-loop model-based visual control
As neuroAI models become better and better aligned to the brain, we’ll start seeing applications of visual neural control. The core idea is to create the right stimulus I(x,y,t) to bring the brain into a desired state. The applications are numerous: like conventional methods of visual communication, we’ll see it used in the arts and for marketing, but also in a variety of areas that have yet to be defined. I imagine a world in which a developer can download an in silico visual model of the brain–think torchvision or huggingface–to generate stimuli that maximize certain desired properties.

People will almost certainly use neuroAI to optimize ad clicks. However, some of the most exciting applications will be in healthcare, to develop therapies for people with neurological disorders and to enhance the well. Many of the application areas I highlighted above are extensions of currently available treatments through conventional visual psychophysics (see Chapter 11 of Dosher & Lu for an overview).
I’m particularly excited about applications in accessibility. Imagine you’re trying to design a font that’s easier to read for people with learning disabilities, like dyslexia, which affect up to 10% of people worldwide. One of underlying issues in dyslexia is sensitivity to crowding, which is the difficulty recognizing letters when they’re presented in the visual periphery because of an interference effect. The visual periphery doesn’t fully represent the visual world: rather, it represents a summary of the visual content, which means it can be confused by letters with similar shapes, like mirror-symmetric letters (e.g. p and q). Anne Harrington and Arturo Deza at MIT are working on neuroAI models that model peripheral processing and getting some very promising results. Imagine taking that model and backpropagating through it to find a font design that is both aesthetically pleasing and is easier to read. With the right data about a specific person’s visual system, we can even personalize the font to a specific individual, which has shown promise in improving reading performance. These are potentially large improvements in quality of life waiting here…
AR and the metaverse
The next trend that will make visual neuroAI applications far more powerful is the adoption of augmented reality glasses. A lot of people are skeptical about the metaverse and whether it is vaporware. Virtual reality remains niche. But I think that augmented reality (AR) is a very different story than virtual reality (VR), because AR integrates into daily life.
The hypothesis of Michael Abrash, chief scientist at Meta Reality Labs–my skip-manager when I worked there–is that if you build sufficiently capable AR glasses, everybody will want them. That means building world-aware glasses that can create persistent world-locked virtual objects; light and fashionable frames, like a pair of Ray-Bans; and giving you real-life superpowers, like being able to interact naturally with people regardless of distance and enhancing your hearing. If you can build these–a huge technical challenge–AR glasses could follow an iPhone-like trajectory, such that everybody will have one (or a knockoff) 5 years after launch.
To make this a reality, Meta spent 10 billion dollars last year on R&D for the metaverse. While we don’t know for sure what Apple is up to, there are strong signs that they’re working on AR glasses. So there’s also a tremendous push on the supply side to make AR happen.
This will make widely available a display device that’s far more powerful than today’s static screens. If it follows the trajectory of VR, it will eventually have eye tracking integrated. This would mean a widely available way of presenting stimuli that is far more controlled than is currently possible, a psychophysicist’s dream. And these devices are likely to have far-reaching health applications, as told by Michael Abrash in 2017:
Consider the glasses I’m wearing. They enhance the acuity of my vision every waking moment. But what it they were AR glasses that enhance perception in other ways as well? What if they could enable me to see in low light? What if I could see people in places on the other side of the world? What if AR glasses could help me live a normal life if macular degeneration–which runs in my family–hits me? (emphasis mine)
The significance for visual neuroAI is clear: we could deliver therapies through stimulus sequences I(x,y,t), in a highly controlled way on a continuous basis in every day life. This is still open-loop control, but it’s vastly enhanced by the delivery method.
It’s easy to think that AR glasses will bring a nightmarish, always-connected world in which our senses are constantly bombarded. But I can imagine AR moving the needle in the opposite way, where I can modify the visual environment to my liking and have complete agency over it. Imagine walking with AR glasses and being able to turn on a focus mode, like noise-cancelling headphones for your vision. To be safe, they would need to let through critical information, which means having environmental awareness as well as a very good model of how your visual system works. Assuming we can overcome the technical hurdles, you could get yourself into a deep work mindset very easily.
BCI
With a great, highly controlled display, you can control the input to the visual system precisely. The next, more powerful stage in delivering therapies through the eyes is to verify that the brain is reacting in the expected way and to adjust the input accordingly. Closed-loop control means measuring in real time how brain states react to stimulation through a read-only brain-computer interface (BCI). We can then nudge the initial brain state s0 towards the desired outcome s1. An analogy will help. Think of how a thermostat works: it controls a heating element. When the temperature hits above a certain threshold, it stops heating until a lower temperature is hit. That way the temperature is always within range. A closed-loop thermostat is strictly more powerful than a heating element that must be manually turned on or off (e.g. a space heater). And it doesn’t require having a very good model of the heat transfer properties of the room or the heater: closed-loop control can be robust to model inaccuracy.
Getting to closed-loop control means having access to brain-computer interfaces that can read brain states. In this scheme, AR glasses are used to stimulate the brain, which is far more practical than invasive stimulation. To stimulate the visual brain at the relevant spatial scale directly via optogenetics or electrodes would likely require a million stimulation sites, which will likely remain technically infeasible in humans over the next decade. We can access a significant number of therapeutically interesting states by controlling the input to the eyes instead. As the visual system accounts for 30% of the brain and it is densely connected to other areas, these other areas should also be partially controllable, as shown in pioneering work by Dani Bessett and colleagues.
There are a number of non-invasive read-only BCIs that are commercialized today or in the pipeline. Some examples include:
- EEG. Electroencephalography measures the electrical activity of the brain outside of the skull. Because the brain acts a volume conductor, EEG has high temporal resolution but low spatial resolution. While this has limited consumer application to meditation products (Muse) and niche neuromarketing applications of dubious scientific value, I’m bullish on some of its uses in the context of vision. EEG can be much more powerful when one has control over the visual stimulus, because it’s possible to correlate the contents of the display with the EEG signal and decode attention (visual evoked potentials methods, VEPs). Indeed, NextMind, which made an EEG-based “mind click” based on VEPs, just got bought by Snap, which is now making AR products. Valve is also making a strong play into integrating EEG into VR headsets through their partnership with OpenBCI. I would not count EEG out.
- fMRI. Functional magnetic resonance imaging measures the small changes in blood oxygenation associated with neural activity. It’s slow, it’s not portable, it requires its own room and it’s very expensive. The only current clinical application of fMRI is in pre-surgical mapping (e.g. to localize speech areas of the brain before surgically removing a tumor). However, fMRI remains the only technology that can non-invasively read activity deep in the brain in a spatially precise way. There are two paradigms which are fairly mature and relevant for closed-loop neural control. The first is fMRI-based biofeedback. A subfield of fMRI shows that people can modulate their brain activity by presenting it visually on a screen. The second is visual cortical mapping, including approaches like population receptive fields and estimating voxel selectivity with movie clips, which allow one to estimate how different brain areas respond to different visual stimuli. These two methods hint that it should be possible to estimate how a neuroAI intervention affects the visual brain and steer it to be more effective.
- fNIRS. Functional near infrared spectroscopy uses diffuse light to estimate cerebral blood volume between a transmitter and a receptor. It relies on the fact that blood is opaque and increased neural activity leads to a delayed blood influx in a given brain volume (same principle as fMRI). It’s been dismissed as being too slow and having too low spatial resolution to make a dent, but with time gating (TD-NIRS) and massive oversampling (diffuse optical tomography), spatial resolution is far better. On the academic front, Joe Culver’s group at WUSTL have demonstrated decoding of movies from visual cortex. On the commercial front, Kernel is now making and shipping TD-NIRS headsets which are impressive feats of engineering. And it’s an area where people keep pushing and progress is rapid; my old group at Facebook demonstrated a 32-fold improvement in signal-to-noise ratio (which could be scaled to >300) in a related technique.
- MEG. Magnetoencephalography measures small changes in magnetic fields, thus localizing brain activity. Portable MEG that doesn’t require refrigeration would be a game changer for noninvasive BCI. People are making progress with optically pumped magnetometers: you can buy a single OPM for $10k from QuSpin. Kernel is teasing an upcoming Flux headset with a large number of OPM modules.
In addition to these better known techniques, some dark horse technologies like digital holography, photo-acoustic tomography, and functional ultrasound could lead to rapid paradigm shifts in this space.
While consumer-grade non-invasive BCI is still in its infancy, there are a number of market pressures around AR use cases that will make the pie larger. Indeed, a significant problem for AR is controlling the device: you don’t want to have to walk around with a controller or muttering to your glasses if you can avoid it. Companies are quite serious about solving this problem, as evidenced by Facebook buying CTRL+Labs for a hefty amount in 2019, and Snap acquiring NextMind. Thus, we’re likely to see some real-life, low-dimensional BCIs (e.g. a mental click) not long after the introduction of AR. Whether high-dimensional BCIs like Kernel’s offerings will rapidly find product-market fit outside of the lab remains to be seen. Companies would need to find a real use case; it’s possible that the kinds of neuroAI therapies I advocate for here are precisely the right use case.
If we can control the input to the eyes as well as measure brain states precisely, we can deliver neuroAI-based therapies in a monitored way for maximum efficacy.
Conclusions
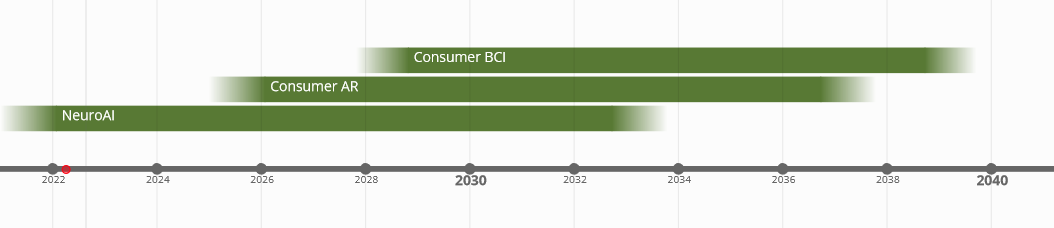
NeuroAI is creating better and better models of the brain, especially sensory systems. A push in the next 10 years will create models which will be excellent stand-ins for the visual brain at the scale which matters for visual perception. While we continue to push to understand the mysteries of vision, excellent in silico models will open up a slew of application areas. Open-loop control already exists, and it will continue to grow as we become better at using it to unlock different applications. AR will bring ubiquitous, world-locked, high-resolution displays to everyday life. BCI, when it ships, will make closed-loop brain control possible. Through visual agency, we can take control over our own visual systems, and by extensions much of our inner lives. The eyes are a window to our brain, and we’ll see exciting applications of that in the next decade.

2 responses to “What’s the endgame of neuroAI?”
[…] instance, I’m interested in using ANNs as models for the brain for the purpose of neural engineering. What I really want is that when I create a virtual lesion in a neural network, it predicts how the […]
[…] might give modellers precisely the data they need to make progress in other corners of neuroAI. I wrote a long read about this idea […]