
2022 was the year of generative AI models: DALL-E 2, MidJourney, Stable Diffusion, and Imagen all showed that it’s possible to generate grounded, photorealistic images. These generative AIs are instances of conditional denoising diffusion probabilistic models, or DDPMs. Despite these flashy applications, DDPMs have thus far had little impact on neuroscience.

I want to change that! I think DDPMs are very cool models. Not only can they be used to generate oil paintings of cute sloth birthday parties, but they’re also useful, general-purpose generative models: tractable, and easy to train. Perhaps surprisingly, they’re also related to a lot of common models in neuroscience, like hierarchical Bayesian predictive coding models and Hopfield networks. They contain a lot of interesting ideas about how the brain might implement complex generative models, and I think they would benefit from being studied from a neuroscience perspective.
I wrote this article both for neuroscientists who want to keep up with the latest in ML, and for ML practitioners who are curious about neuroscience. First, I give a high-level overview of diffusion models, how to train them and how they compare and contrast to other generative models. I won’t get into the math but I’ll give references to tutorial introductions if you’re interested in that. I’ll discuss current applications in neuroscience, and speculate about some potential future applications. Finally, I’ll relate the structure of DDPMs to some common neuroscience models like Hopfield networks and Bayesian predictive coding. Let’s get started!
Subscribe to xcorr and be the first to know when there’s a new post
How DDPMs work
DDPMs are generative Probability Models: they learn a complex probability distribution p(x0) from empirical data. Here x is a D-dimensional vector representing an image, sounds, time series, graphs, etc. To generate a new sample from a learned DDPM, you repeatedly apply a Denoiser – a deep neural network like a U-Net or a transformer – to noise vectors. Think of these noise vectors as the latent variables of the model. At the end of the process, a sample is generated. It’s a little bit like pareidolia (seeing faces in clouds): if I present a bunch of noise stimuli (e.g. clouds) to a human, and ask them what they see, they’ll generate a probability distribution over familiar things (e.g. faces). This process thus maps noise to a learned probability distribution.
Training a DDPM
This section follows the exposition from Kevin Murphy’s second book, Probabilistic Machine Learning: Advanced Topics. A free draft of the book is here. Another great resource is Calvin Luo’s blog post.
But how do you learn a DDPM? Rather than repeat all the math from other excellent tutorials, I will to give you a flavour of why DDPMs are built the way they are, how they’re trained, and give you a bit of wayfinding so you can learn independently.
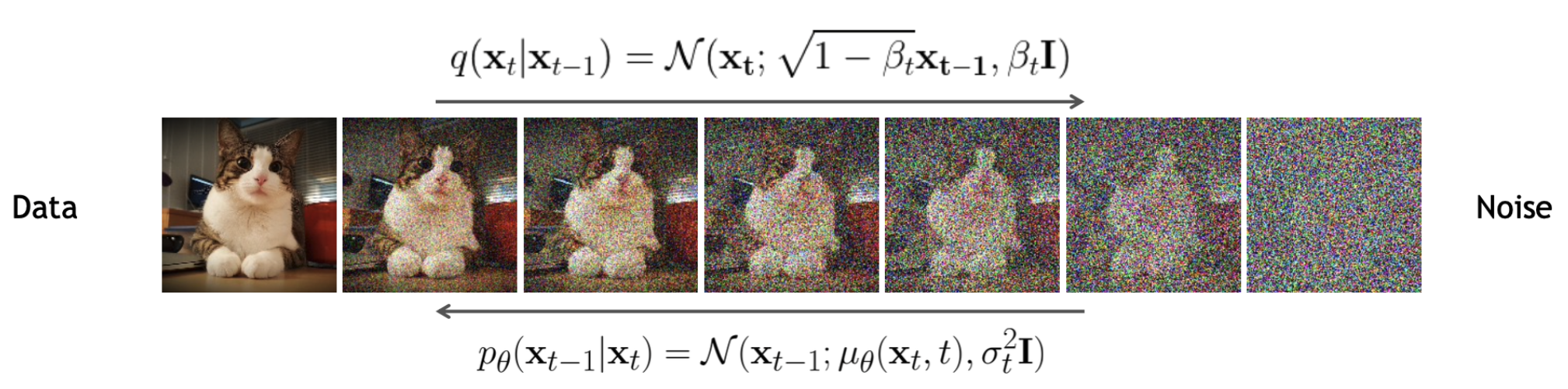
Training DDPMs involves two diffusion processes. First, a word of warning: the diagram that you will see in every DDPM paper to illustrate these processes, by convention, has samples on the left (x0), and noise on the right (xT). I think that’s very confusing, because usually we’re going from noise to sample (right to left), and the diagram breaks expectations about how you should read it, so watch out for that.
Let’s talk about the forward process first (left to right): Take any probability distribution and add a little bit of normal noise to it, while also rescaling it; if you repeat this process enough times, you will obtain a normal distribution. This is a consequence of the central limit theorem. This process is Markovian (q(xT) = Π q(xt|xt-1) q(x0)). Each of the probability distributions in this expression has a simple Gaussian functional form, save for q(x0).
Our goal is to learn the reverse process: going from noise to samples, right to left. We write another Markov chain, p(x0) = Π p(xt-1|xt) p(xT). If we want p(x0) to approximate q(x0), the diffusion kernel p(xt-1|xt) has to be different for different xt: it has to be a biased diffusion process, otherwise we’d just turn noise into noise. We keep the same functional form for the diffusion kernel – a normal distribution – but we make its mean depend on xt via a deep neural network μ(xt, t).

It doesn’t seem like we’ve accomplished much thus far, but here comes the magic: you can write down an expression for the likelihood of different samples (q(x0)) in terms of ratios of p’s and q’s. You can lower-bound these expressions using Jensen’s inequality – the ELBO, or evidence lower bound, the same trick used in VAEs – and now you’ve got an expression involving the KL divergences of different Gaussian distributions. All of these KL divergences can be calculated symbolically, a bunch of stuff cancels out, you’re left with a really simple expression for the ELBO. It turns out you can then optimize using this straightforward algorithm:

Here, ϵ(x) is a deep neural network (a U-Net or transformer) that takes a sample and predicts the noise that was added into it: the denoiser. The DDPM learning algorithm holds in five lines of pseudo-code. It’s quite accessible for us mere mortals: you can code and train a DDPM in an afternoon. Yet, the structure of a DDPM is quite rich, and it is very flexible. That’s a big reason why I find DDPMs so interesting.
Sampling
Sampling is done by running the learned denoising process many times, starting from noise samples p(xT). You denoise, add a little bit of noise, denoise, add a little bit of noise, etc. until you have a sample. That can be pretty slow, but there are strategies to accelerate. The most common is probably DDIM (the I is for implicit), which removes the continuous addition of noise with a modified sampling chain. With DDIM, you only take one noise sample p(xT), and the rest of the chain is deterministic. It’s possible to take DDIM samples from a vanilla-trained DDPM; you can reduce the number of sampling steps from, say, 1024, down to a more manageable 16 or so without much loss in sample quality. Because DDIM sampling is deterministic after the initial noise injection, it preserves the latent structure of the model, so you can use it for things like latent space interpolation.
So far I’ve focused on unconditional DDPMs, but it’s just as easy to build a conditional DDPM. The most common way to condition during training and generation is to take the conditioning information, pass it through an MLP, and let it bias the denoiser every denoising iteration. The timestep t is also embedded in this way. Biasing can be done by changing the mean and scale of different feature maps of the U-Net, or by biasing attentional blocks. This mechanism is very flexible; to take a specific example, latent diffusion, which drives Stable Diffusion, can condition on:
- text via a dense CLIP-based embedding
- one-hot encoded image categories
- segmentation masks
- other images (e.g. for image-to-image translation or upsampling)

There’s an additional way of conditioning DDPMs only at generation time. This late-binding is a bit of a mindfuck so bear with me or skip to the next section. The DDPM likelihood (reverse chain) can be multiplied with other distributions (e.g. priors) easily. Because each diffusion step moves the distribution only a little, it turns out that multiplying by a prior ends up only changing the mean of each diffusion step (see Appendix Table 1 in Sohl-Dickstein 2015). That means you can add a late-bound generation “penalty” (the log of the prior) to bias the generation. This trick is used in both classifier-guided diffusion and classifier-free guided diffusion to improve visual quality of generation. Basically, they bias the generation process away from low-quality, easily confusable images towards canonical, visually striking poses.

This late binding opens up many possibilities: sometimes you need to generate images which are just slightly off of the image manifold. Here I show a toy example of using a late-bound critic to make a batch of samples more easily discriminable from each other. I trained a vanilla DDPM on Google Fonts to generate lowercase letters. Next, I used the intermediate layer of an AlexNet to generate a confusion matrix to determine how likely AlexNet is to confuse these letters (see Janini et al. 2022 for background information). Then I nudged the generation so that letters are less confusable according to this critic, creating a modified font with improved readability in peripheral vision. This kind of late binding is very hard to do with other types of deep generative models.


How DDPMs compare and contrast to other generative models

It can be hard to keep track of all the deep generative architectures and all their plusses and minuses: when should you use one versus another? DDPMs are frequently used in lieu of a GAN or a VAE. Compared with GANs:
- DDPM samples, like those from GANs, can be of very high visual (or auditory…) quality
- DDPMs can sample from the actual distribution of the data; GANs can suffer from mode collapse
- It’s really easy to train a DDPM, unlike a GAN which can suffer from instability
- You can calculate a likelihood lower bound for a given sample in a DDPM, unlike a GAN
- However, DDPMs are slower to sample (though tricks like DDIM help)
DDPMs are quite similar under the hood to hierarchical VAEs. Compared with vanilla VAEs however, DDPM samples are sharper.
Another thing that differentiates DDPMs is that they have some unusual capabilities out of the box. That means that, for instance, they can denoise images out of the box. Upsampling, inpainting and outpainting are also straightforward.
They do have one big drawback compared to GANs and VAEs: the latent space of a vanilla DDPM has the same dimensionality as the data (e.g. the number of pixels). This is different than GANs or VAEs which typically have compressed latents. For some applications, compression is the whole point: see my previous post on dimensionality reduction in neuroscience. A notable exception to this rule is latent diffusion, which uses a complex pipeline involving a VQ-GAN in addition to diffusion in the compressed space; but technically, it’s not the diffusion model that learns the compressed latent, it’s the GAN. That being said, as discussed above, while DDPMs don’t have compressed latents, they do have high-dimensional latents which can be manipulated and interpolated.
TL;DR: DDPMs are easy to train, they generate high-quality samples, and they have some unusual properties which allow them to be used in interesting scenarios. However, they don’t have compressed latents, so we can’t use them for dimensionality reduction. That’s unfortunate for us neuroscientists because we love dimensionality reduction. So what can we use them for?
What are they good for (in neuroscience)?
Generating brain-data-conditioned samples
There are neuroscience applications which require generating high-quality samples. Brain decoding is a good example: you attempt to back out what a person saw (or imagined, or even dreamt) from the pattern of their brain activity. Ideally, you’d like to generate natural-looking samples. Two recent papers (Chen et al. 2022, Takagi & Nishimoto 2022), which I reported on in the last post, demonstrate these ideas. They mapped fMRI data to the latents of a latent diffusion model to decode images from the brain. You could imagine doing this with single neuron data as well (e.g Bashivan et al. 2019, Ponce et al. 2019).

This Brain DALL-E idea is very cool, but you might think it’s a curiosity rather than a practical idea. However, there’s a domain where generating good, brain-conditioned samples is essential. Patients with ALS or brainstem strokes can end up in a locked-in state, where they’re unable to communicate despite remaining fully conscious. This was eloquently documented in the book The Diving Bell And The Butterfly, which was dictated, letter by letter, through a series of eyeblinks by the author Jean-Dominique Bauby. It’s been recently demonstrated that we can an invasive brain-computer interface can directly read attempted speech from a patient’s brain. Moses et al. (2021) demonstrated decoding brain activity in speech-motor cortex in a locked-in patient, classifying attempted spoken words and displaying them on a screen, thus allowing the patient to communicate.
You could imagine pushing this idea forward by making a custom voice box for the locked-in patient. First, capture a patient’s voice and intonation in a generative model, similar to the recent VALL-E (VALL-E is a VQ-VAE, but you could also do this with a DDPM). In the case of a neurodegenerative disease, it should be possible to record a patient’s voice after the diagnosis but before being locked-in. Then one could create a voice-box BCI that sounds like the patient’s own voice, which can be deployed once the patient is unable to communicate. It sounds like science-fiction, but I don’t think this is far off.
MRI, medical images and data augmentation
We’ve seen a number of papers applying DDPMs to medical imaging and MRI data. This is less neuroscience-proper and more neurology, but you can see how these ideas could be adapted and used as neuroscience tooling. Consider a compressed sensing scenario, where one wants to infer images from sparse measurements, for example to accelerate an MRI or PET scan. It’s easy to rig up a conditional diffusion model that takes, for example, an undersampled k-space representation of an MRI and spits out a plausible corresponding brain image. Not only are these images visually plausible, they come with their own error bars! It’s indeed possible to run the diffusion process several times to get multiple samples from the posterior and figure out where the model is certain of its reconstruction and where the model is just spitballing. A related application is in denoising images, whether these images are MRIs, PET scans or microscopy images (including 2p-imaging).
Because we can evaluate the likelihood of an image through a diffusion model, we can do anomaly detection, for instance to determine whether there’s a tumour in an MRI. Another application area is label-efficient segmentation. The image-space diffusion process means that the network must learn foreground/background relationships or object boundaries implicitly (this is a bit of foreshadowing for our section on how DDPMs are brain-like). Baranchuk et al. (2022) show how you can use this to do label-efficient segmentation, which could be expanded to medical images or MRIs, which are normally extremely expensive to annotate.
Indeed, data augmentation is something that DDPMs excel at. Learn an unconditional generative model for segmentation masks, learn a conditional generative model for an MRI, and you’ve got yourself a sequence of models that can generate fake (segmentation, MRI) pairs, which you can then use for downstream classification, defining biomarkers, etc.
Why DDPMs might be a little brain-like
We’ve covered sober applications of DDPMs for neuroscience. If DDPMs become just another tool in the toolbox of neuroscience, that’s a win for neuroscience. However, I’d like to go further and claim that DDPMs might be a little brain-like. This is still highly speculative (read: half-baked), but I think there’s a real opportunity to use DDPMs as a wedge to build new neuroAI models of the brain. I’m putting this out there not as a fully worked-out proposal but to make the community aware of the opportunity and find potential collaborators.
Hierarchical Bayesian predictive coding
Let’s consider the current state of visual neuroAI. Convolutional neural networks trained for image classification on ImageNet have been the de facto default models of the ventral stream of the visual cortex – V1, V2, V4 and IT – over the last decade. Self-supervised models have recently been shown to be just as good as supervised CNNs at explaining the ventral stream, and are more biologically plausible (see previous post on this subject). However, we know many ways in which the ventral stream is different than feedforward neural nets trained with supervised or self-supervised learning. Here are 4 facts we need to reconcile with the ventral stream:
- The ventral stream has feedforward, recurrent and feedback connections, while CNNs only have feedforward connections
- The ventral stream (and all of the brain) is noisy, CNNs are deterministic
- The ventral stream is involved in visual imagery during waking, and in dreams; I have no idea how to get a CNN to dream
- The ventral stream and humans as a whole seem to act as though vision is Bayesian; it’s not clear to me that CNNs do the same kind of Bayesian inference
We can add more features to a basic CNN to better match the ventral stream. For instance, recurrent connections allow computations to unfold in time. While there’s nothing wrong with empirically motivated additions to CNNs, it’d be nice for additions to be more theoretically grounded.
Prior to CNNs taking over the study of the ventral stream, a dominant view of the visual cortex was as a hierarchical Bayesian inference machine (see this workshop for historical perspectives). A prototypical example is the proposal of Mumford and Lee (2003):
In this framework, the recurrent feedforward/feedback loops in the cortex serve to integrate top-down contextual priors and bottom-up observations so as to implement concurrent probabilistic inference along the visual hierarchy. We suggest that the algorithms of particle filtering and Bayesian-belief propagation might model these interactive cortical computations.
In Mumford and Lee’s model, the brain is Bayesian (point 4), it contains a generative model (point 3), and inference of the contents of an image from noisy measurements from the retina involves recurrent noisy algorithms (points 1 and 2). These recurrent noisy algorithms include particle filtering, loopy belief propagation, or MCMC. There was some early progress in scaling up this idea: the restricted Boltzmann machine (RBM) papers from Bengio & Hinton from the late 2000’s cite Mumford & Lee. However, the idea fizzled as discriminative approaches to classification became popular. Generative approaches are currently not competitive in explaining the ventral stream compared to other image-computable models (Brain-Score and the like; see also Conwell et al. 2021, Zhuang et al. 2021).
I think there’s an opportunity to resurrect and modernize this class of models using DDPMs. The most straightforward mapping to the ventral stream is to think of the first half of the denoising U-Net as equivalent to a feedforward pass up the ventral stream, the second half as a backward pass; the multiple iterations of the denoiser correspond to recurrent activity. The information communicated at every denoising step back to V1 is the delta between an image and its projection on the image manifold at this point in the process, producing a nice link to predictive coding models.
Regardless of the exact way in which we embody these ideas, DDPMs give us access to a lot of new machinery to work with, in both discrete & continuous formulations. That’s on top of related ideas of denoising score matching on probabilistic graphic models and related progress in hierarchical VAEs (see Kevin Murphy’s book for more on these subjects).
Content addressable memories and the hippocampus
DDPMs are also related to ideas about content addressable memories and the hippocampus. Consider the famous Hopfield network, a recurrent neural network which stores discrete memories inside of its weights. It can retrieve memories at will as the steady state of recurrent activity: starting from an incomplete pattern, it can complete the pattern by repeated application of a simple rule. Such a content-addressable memory is often a core component of computational models of the hippocampus, for instance the Tolman-Eichenbaum machine.

I like to think of DDPMs as continuous content-addressable memories. Corrupted images can be retrieved by the repeated application of the denoiser. Importantly, the network stores continuous memories: instead of representing discrete memories (mixture of Dirac deltas) like a Hopfield network, they represent an ensemble of memories (continuous distribution). DDPMs can recover from different corruptions, including additive noise and masking.
Lest we think that this analogy is a bit vacuous, DDPMs are capable of complex tasks traditionally ascribed to the hippocampus. A striking example is the recent work from Harvey et al. 2022, who showed that you could train a DDPM to generate hour-long videos. They took videos of a car driving in a virtual environment, and let the DDPM learn conditional generation, for example predicting the next frame in a sequence from the previous 4. By repeating this process with different temporal horizons, the model could generate hour-long videos of a car driving through the town, starting from a random location hallucinated by unconditional sampling (see samples here).

It’s really quite striking that this simple model learned to generate complex sequences from scratch. In fact, it’s possible to map back hallucinated sequences to locations within the virtual town where the sequence was generated, and in most cases, the sequences are spatially coherent. Occasionally, the denoiser gets confused and warps to a different part of the map, relying on landmarks to do its thing. I think it’s really interesting how the generative task learned by the DDPM coaxes it to memorize and navigate through an environment, and how this could relate to the hippocampus’ role in navigation and memory.
As separate objects of study
I hope to have convinced you that DDPMs are sufficiently analogous to the brain to advance the neuroAI research programme. However, if it turns out, after careful study, that these machines are mechanistically quite different than the brain (Marr’s level 3), they might still contain some insights about the brain’s goals and potential algorithmic solutions (Marr’s levels 1 and 2). I think that neuroAI and AI itself would benefit from studying how DDPMs work and what they’re capable of. There are some really interesting potential insights into human visual cognition lurking inside these models.

For example, I’ve mentioned previously that DDPMs are useful for unsupervised segmentation. As part of their objective to model the distribution of natural images, they perform what appears to be implicit, approximate segmentation, propagating information about object relationships across long distances, all in the service of generating spatially coherent images. This opens up a number of follow-up questions, for example, are DDPMs susceptible to foreground/background illusions, like Kanisza squares? Can they solve Mooney images and follow Gestalt rules? We can take recent criticisms of feedforward CNNs as models of vision as compendia of interesting phenomena that should be investigated in DDPMs. Tantalizingly, DDPMs can be easily made robust to adversarial examples, one of the commonly highlighted drawbacks of discriminative accounts of perception.
Of key importance in these investigations is carefully controlling the natural image dataset DDPMs are trained on. ImageNet is not representative of what’s ecologically relevant to primates: it has too many dogs and not enough faces and body parts. Using ImageNet might be acceptable when the task is just a means to an end (e.g. learning good general-purpose features in a self-supervised manner), but not when the task is learning the manifold of images. We should carefully comparatively study DDPM behaviour trained on ImageNet or LAION vs. ecologically motivated datasets, e.g. EcoSet and SAYCam.
Conclusion
DDPMs are a class of conditional generative models that have found widespread use in generating images, sounds and time series. They strike a nice balance between complexity of implementation, flexibility, ease of sampling and evaluation. They may be useful in neuroscience where we need to generate fake data – for semi-supervised learning or for decoding. However, there’s a wider and more speculative horizon of possible links to neuroscience: hierarchical Bayesian models and content-addressable memories. It’ll be really interesting to break these models apart and figure out how they really work.
