
We’re in a golden age of merging AI and neuroscience. No longer tied to conventional publication venues with year-long turnaround times, our field is moving at record speed. 2021 saw a Cambrian explosion of research into unsupervised learning to explain brain representations, which is teaching us about how the brain might have evolved for sensing. Join me on this tour of this exciting new research area.
Alternative format: If you’d rather listen than read, I gave an interview to Yannic Kilcher covering this post (1h20m).
Supervision be gone
One of the most robust findings in neuro-AI is that artificial neural networks trained to perform ecologically relevant tasks match single neurons and ensemble signals in the brain. The canonical example is the ventral stream, a series of areas in the visual cortex of mammals selective for shape. DNNs trained for object recognition on ImageNet match representations in IT, an area of the ventral stream (Khaligh-Razavi & Kriegeskorte, 2014, Yamins et al. 2014). Supervised, task-optimized networks link two important forms of explanation: ecological relevance and accounting for neural activity. They answer the teleological question: what is a brain region for?
However, as Jess Thompson points out, these are far from the only forms of explanation. In particular, task-optimized networks are generally not considered biologically plausible. Conventional ImageNet training uses 1M images. For a human infant to get this level of supervision, they would have to receive a new supervised label every 5 seconds (e.g. the parent points at a duck and says “duck”) for 3 hours a day, for more than a year. And what about a non-human primate or a mouse? How would they receive a supervisory signal? Thus, the search for biologically plausible networks which match the human brain is still on.

This year, we’ve seen a lot of headway into finding ways around supervision, and alternatives to supervised training are now competitive.
Subscribe to xcorr and be the first to know when there’s a new post
Unsupervised, self-supervised, contrastive, multimodal
The alternatives to supervised training are many, and it’s not clear which method is winning right now. Let’s review the methods:

- Unsupervised learning aims to represent the data distribution. I’ve covered some unsupervised techniques in the context of dimensionality reduction in neuroscience.
- Self-supervised training aims to find good data representations by solving pretext tasks (figure above). Many have been proposed over the years. Language models are almost universally trained with self-supervision; think BERT and GPT-3.
- Contrastive learning is a particular flavor of self-supervised learning where the pretext task is to predict whether a sample is from a positive or negative (or distractor) class (hence “contrast”). There are many different flavors of contrastive learning: MoCo, InfoNCE, SimCLR, CPC, etc. There are also closely related non-contrastive methods that do away with negative samples, including BYOL and BarlowTwins.
- Multimodal learning is a particular flavor of self-supervised training which aims to find a common subspace for two different modalities (e.g. vision, text, audio, etc.) by predicting one from the other, or predicting a common subspace. CLIP is perhaps the most famous multimodal network – it’s trained contrastively.
All of these methods allow us to learn a representation without the need for pesky supervision. If it turns out that this representation is aligned to a brain area, this is a win, as self-supervised and unsupervised methods are more biologically plausible than supervised methods.
Papers
I went through and reviewed papers and preprints published in 2021. I covered MAIN conference, NeurIPS, CCN, as well as whatever papers and preprints happened to show in my Twitter feed. Of course, this review reflects my research interests (heavily skewed towards a certain flavor of neuro-AI and vision), but I hope it’s useful to many of you who want to see where the field is going.
Unsupervised neural network models of the ventral visual stream

Zhuang and colleagues (2021). This paper was just published in PNAS this year and already has > 60 citations. They found that unsupervised and self-supervised methods learned representations that are well-aligned to ventral stream (V1, V4, IT) neurons. Their significance statement:
Primates show remarkable ability to recognize objects. This ability is achieved by their ventral visual stream, multiple hierarchically interconnected brain areas. The best quantitative models of these areas are deep neural networks trained with human annotations. However, they receive more annotations than infants, making them implausible models of the ventral stream development. Here, we report that recent progress in unsupervised learning has largely closed this gap. We find the networks learned with recent unsupervised methods achieve prediction accuracy in the ventral stream that equals or exceeds that of today’s best models. These results illustrate a use of unsupervised learning to model a brain system and present a strong candidate for a biologically plausible computational theory of sensory learning.
In particular, they found that SimCLR and other contrastive learning methods could explain ventral stream neurons almost as well as supervised methods. Very strong proof-of-concept that labels are not necessary; major milestone for the field IMO.
Beyond category-supervision: Computational support for domain-general pressures guiding human visual system representation

Konkle and Alvarez (2021), bioRxiv. This paper asked a similar question to the Zhuang et al. paper: can the ventral stream be accounted by a network trained without supervised learning? They used fMRI in humans rather than single neuron recordings to evaluate this. They find results which are broadly compatible with the Zhuang paper, with their own flavor of instance-contrastive self-supervision, as well as other along the same lines (SimCLR) accounting for the fMRI data. Interestingly, they find a disconnect between ImageNet classification accuracy and match to fMRI data. This paper has a really interesting discussion, where they seriously consider how you would actually implement self-supervision in a brain. They identify retinal distortions, saccades (see also this recent NeurIPS paper), efference copy, as well as a hippocampus-based buffering mechanism as means of instantiating self-supervision. I would love to see a modelling study instantiating these ideas – I’m sure they’re already on it!
Your head is there to move you around:
Goal-driven models of the primate dorsal pathway
Mineault et al. (2021). Excited that we got this accepted as a spotlight in NeurIPS this year. As I’ve discussed previously, ventral stream neurons are selective for shape. However, there’s an entirely separate stream, the dorsal stream, which is highly sensitive to motion. How does that work? I compared a number of supervised 3d (spacetime) networks to different dorsal stream areas and found that they could not account for the responses of single neurons in non-human primates. Taking the task-driven paradigm at face value, we asked: what kind of task would create the representations we see in the dorsal stream? I trained a network to estimate the parameters of the self-motion of an agent from the patterns of images falling on its retina. Image sequences were generated in Airsim, an Unreal-based simulation engine for drones (below).
The resulting network looked a lot like the dorsal stream, and this was true both qualitatively and quantitatively. The model recapitulated the hierarchy of the dorsal stream (direction selective cells, pattern cells, optic flow cells), while also predicted biological neural responses better. Now, the training of this model is supervised, but from the agent’s perspective, it’s self-supervised, multimodal learning. The agent learns to predict the parameters of its self-motion (vestibular, efference copy) from another modality (vision). That’s potentially biologically plausible, something we’ll be able to verify in NHP experiments to follow.
The functional specialization of visual cortex emerges from training parallel pathways with self-supervised predictive learning
Bakhtiari et al. (2021). This was our second spotlight in NeurIPS this year – I am very grateful to Shahab, who really outdid himself with this one! Mammals have both dorsal- and ventral-like streams, whether it’s humans, non-human primates or mice. Can one artificial neural network explain both? Shahab used a contrastive predictive coding (CPC) network trained on movie clips and found that, with two separate parallel pathways, the network self-organized into a dorsal and a ventral stream. The dorsal stream pathway provided a nice match to mice dorsal areas, and the ventral stream was well matched to ventral stream. What’s more, networks trained with supervision, or networks with just one pathway did not match the brain of mice. I think it’s a very nice embodiment of the idea that with anatomical priors and a sprinkling of self-supervision, the brain can bootstrap itself into existence.
Shallow Unsupervised Models Best Predict Neural Responses in Mouse Visual Cortex

Nayebi et al. (2021), bioRxiv. Deep neural nets are great models of primate visual cortex, but not so much for mice. This paper asks the question of how we can obtain better models of mouse vision using more ethologically relevant, more anatomically grounded models. They used mouse visual cortex data (static images) and compared it to supervised and self-supervised networks of different architectures. One interesting finding is that shallow networks with parallel branches explain mice data better. This corroborates Shahab’s findings. They make the argument that mice’s visual brain is a shallow “general purpose” visual machine, which is good for a variety of tasks, unlike the deep neural network in our brains, which is highly specialized to subtasks. I think these ideas fit very nicely with the idea that different brains are adapted to different ecological niches, which is one of my favorite theories of everything in neuroscience.
Neural Regression, Representational Similarity, Model Zoology & Neural Taskonomy at Scale in Rodent Visual Cortex

Conwell et al. (2021), NeurIPS. Another paper on self-supervised learning in mouse visual cortex. This one is notable for the breadth of metrics and models considered: vision transformers, MLP mixers, taskonomy encoders, self-supervised models. Broadly speaking, the results are compatible with the previous two papers. I think the most notable finding is that some ethologically relevant taskonomy tasks stood out as better aligned to the brain: 2d segmentation, object recognition and semantic segmentation. Perhaps the mouse’s visual brain receives some multi-modal self-supervision from the whiskers?! It’s a very cool idea that an experimentalist should pick up.
Partial success in closing the gap between human and machine vision

Geirhos et al. (2021), NeurIPS. Humans are very good at performing classification of images under distortions, such as noise, changes in contrast, rotations, etc. Up to now, CNNs have performed poorly on this task. In this paper, they ask the question of whether newer models have closed this gap. Indeed, they have! They find that newfangled self-supervised and multimodal models are now at par with humans when it comes to robustness to distortions. One important factor underlying the results is how much data the network was trained on: models trained with orders of magnitude more data are more robust. CLIP performs exceptionally well here, for reasons that are still not clear. Newer models are also less sensitive to texture and more to shape: they seem to be taking less shortcuts. Nevertheless, newer models still make distinctly non-human mistakes, which they were able to show with extensive psychophysics. Very thorough evaluation, the reviewers loved it and so did I.
Multimodal neural networks better explain multivoxel patterns in the hippocampus

Choksi et al. (2021), SVHRM workshop. The hippocampus contains “concept cells” (e.g. the infamous Jennifer Aniston cell) that are highly multimodal; they will respond to a textual representation of a concept or an image. Interestingly, CLIP does the same, and in fact can be fooled by adversarial labels (i.e. writing wrong labels into an image). In this workshop paper, the authors use publicly available fMRI data to show that multimodal networks, including CLIP, explain hippocampal data best. It’s wild that there’s something so special about CLIP, and we still don’t know what it means!
Unsupervised deep learning identifies semantic disentanglement in single inferotemporal neurons
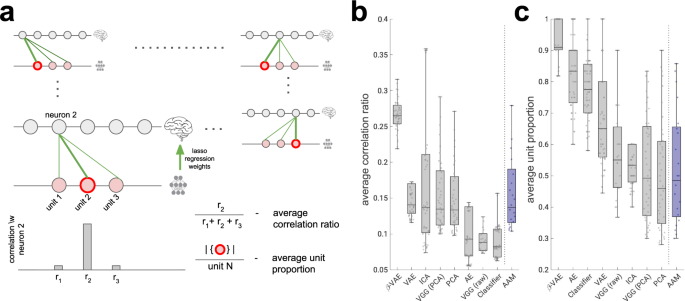
Higgins et al. (2021), Nature Comms. The Deepmind gang is at it again comparing neural representations in face selective areas and unsupervised, disentangled neural networks. They ask whether single, face-selective neurons in IT are aligned to single disentangled causal factors. Perhaps a single neuron in IT encodes a single causal factor which affects the appearance of faces, e.g. skin tone, lighting, age, etc. The manifold perspective of neural representation, OTOH, is that neurons don’t have to be axis-aligned to represent interesting factors; arbitrary rotations of the latent factors are just as good candidates for representation. This would argue against axis-alignment.
They trained an unsupervised neural network, the beta-VAE, to represent faces. A beta-VAE is a variational auto-encoder (VAE) with a higher weight (=beta) on the KL term, which encourages the representation to be disentangled. They show in this case that single neurons in IT are aligned to single disentangled latent factors in the VAE, which argues against the manifold view and for the disentangled causal graph view. Like all good papers, asks more questions than it answer: how does disentangling happen in the brain? How do people learn disentangling? What’s the advantage of a disentangled representation?
Unsupervised learning predicts human perception and misperception of gloss

Storrs et al. (2021), Nature Human Behaviour. This paper examines the question of how humans perceive gloss from surfaces. They train a pixel-VAE on an ensemble of textures and examine how the latent factors are aligned to how humans perceive surfaces. They find that the VAE naturally disentangles different factors, and furthermore, is well aligned to human perception! Furthermore, they find that supervised networks don’t perform nearly as well on this task. Very cool idea, and lots of nice psychophysics in this paper.
Conclusion
This year has seen huge advances in matching unsupervised and self-supervised models to brains. They offer a number of advantages over the alternatives: potentially a better match to brain data, they can be trained without labels.
We have to be careful though: learning without labels is better than with labels, but we still have to run through the numbers to see if the math works out. In particular, because labels are expensive, and self-supervision opens the door for learning without labels, the latest class of models often uses a tremendous amount of data for training. For instance, GPT-3 is trained on essentially all the text that’s ever been produced by humanity (~500 billion tokens). By contrast, children in the most talkative homes are exposed to ~30M words by the time they’re five. If we find an alignment between GPT-3 and representations of language in the human brain, it doesn’t follow that contrastive training on an immense corpus as in GPT-3 is a biologically plausible mechanism for language acquisition and representation; we’re still off by 4 orders of magnitude.
2022 will hopefully see a lot of work on embodied learning in ecologically valid settings. This, mixed with biologically plausible self-supervised and unsupervised learning, will lead to more refined models of how the brain can learn good representations during evolution and development.

5 responses to “Unsupervised models of the brain”
[…] as good as supervised CNNs at explaining the ventral stream, and are more biologically plausible (see previous post on this subject). However, we know many ways in which the ventral stream is different than feedforward neural nets […]
[…] Learn more: Read the 2021 year end review. […]
[…] Previous Unsupervised models of the brain […]
Yes, please post more blog articles!
Yes, I’d love to see another post in this series!